Knuth-Morris-Pratt 算法,简称 KMP 算法,由 Donald Knuth、James H. Morris 和 Vaughan Pratt 三人于 1977 年联合发表
KMP 算法主要应用于 字符串匹配
基本思想:当出现字符串不匹配时,可以利用前面已经匹配的那些字符中的信息,避免从头再做匹配
以 在文本串中查找是否出现过一个模式串 为例:
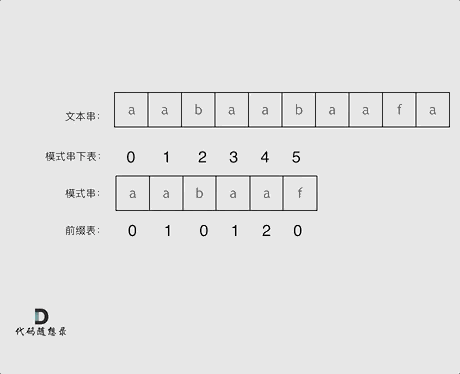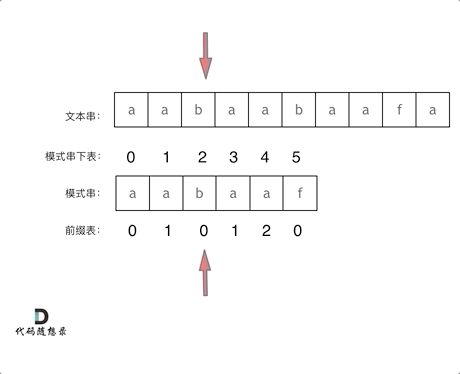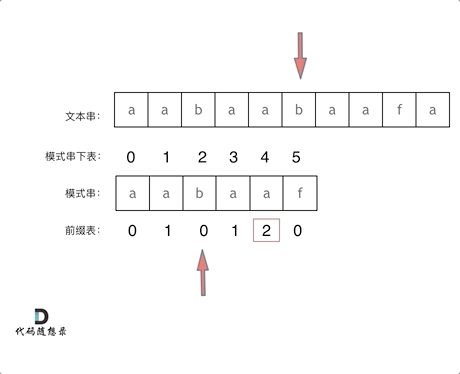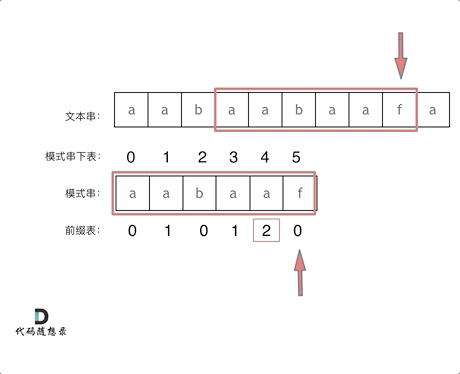
检测文本串 "aabaabaaf" 中是否含有 模式串 "aabaaf",KMP 算法的查找过程如下所示
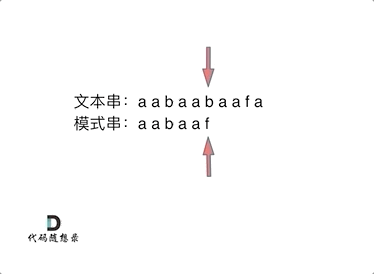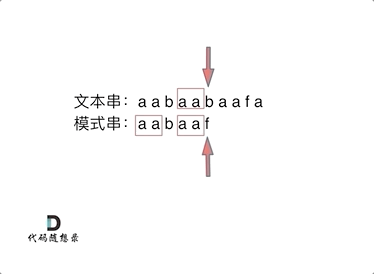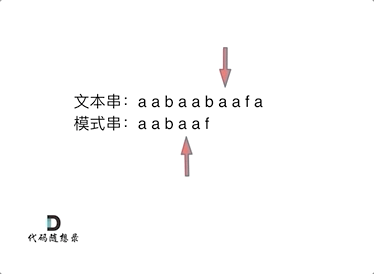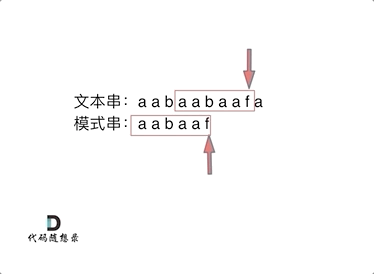
令 表示文本串长度, 表示模式串长度,暴力匹配的时间复杂度为 ,而 KMP 算法的时间复杂度为
- 计算模式串的前缀表的时间复杂度为
- 与文本串进行匹配的时间复杂度为
# 前缀表
前缀表(prefix table)是用来回退的,它记录了之前已经匹配的文本中的信息,并告诉我们:当文本串中的字符 x 与模式串中的字符 y 匹配失败时,下一步应该将模式串中的哪个字符与文本串中的字符 x 重新进行匹配
<!-- 前缀表中,下标为 i 的元素,记录了 “ 在模式串里边,以下标 i 结束的子串有多大长度的相同前缀后缀,即,相同前后缀的最大长度 ” -->
对于长度为 的字符串 s ,前缀表下标为 i 的元素记作 , 表示 s 的子串 s[0:i] 的最长的相同前后缀的长度
next 数组就是一个前缀表
# 前缀与后缀
字符串的 前缀 (prefix):不包含最后一个字符 的、以第一个字符开头 的连续子串
- 例如,字符串 "aabaaf" 的前缀有:"a"、"aa"、"aab"、"aaba" 和 "aabaa"
字符串的 后缀 (suffix):不包含第一个字符 的、以最后一个字符结尾 的连续子串
- 例如,字符串 "aabaaf" 的后缀有:"f"、"af"、"aaf"、"baaf" 和 "abaaf"
# 最长相同前后缀
针对某一字符串,使得 前缀和后缀相同 的前缀 / 后缀长度的最大值,即为所谓的 相同前后缀的最大长度,对应的前缀 / 后缀即为 最长相同前后缀
例如,字符串 "aabaa" 的前缀有 "a"、"aa"、"aab"、"aaba",后缀有 "a"、"aa"、"baa"、"abaa",其中,相同前后缀的最大长度为 2,最长相同前后缀为 "aa"
# 前缀表元素
以模式串中位置 i 为结尾的子串 s[0:i] ,其相同前后缀最大长度,就是前缀表元素 ,其中,
以模式串 "aabaaf" 为例:
- 子串 "a" 的相同前后缀最大长度为 0(没有前缀,也没有后缀),
- 子串 "aa" 的相同前后缀最大长度为 1(前缀为 "a",后缀也为 "a"),
- 子串 "aab" 的相同前后缀最大长度为 0(前缀不含 'b',后缀一定含 'b' ,不存在相同前后缀),
- 子串 "aaba" 的相同前后缀最大长度为 1(最长相同前后缀为 "a"),
- 子串 "aabaa" 的相同前后缀最大长度为 2(最长相同前后缀为 "aa"),
- 子串 "aabaaf" 的相同前后缀最大长度为 0(前缀不含 'f',后缀一定含 'f' ,不存在相同前后缀),
即,
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 模式串 | a | a | b | a | a | f |
| 前缀表 | 0 | 1 | 0 | 1 | 2 | 0 |
在字符串匹配过程中,如果模式串的 f 与文本串匹配失败,则需找到 f 前一位所对应的前缀表元素,其值为 2 ,因此,可以将模式串下标为 2 的字符与文本串重新匹配
- 字符
f之前的这部分字符串(也就是字符串 "aabaa" )的最长相等前后缀字符串是 "aa" ,匹配失败的位置是后缀子串的下一位,那么我们找到相同前缀的下一位继续匹配即可
# next 数组
next 数组,即,前缀表的一种实现
确定字符串的 next 数组,也就是在 寻找最长相同前后缀
# 基本思想
针对每一个以索引 suffixEnd 结尾的子串,将 suffixEnd 作为后缀的末尾索引,寻找末尾字符为 s[suffixEnd] 的前缀(即,寻找能够与后缀匹配的前缀)
# 算法流程
初始化前缀末尾 prefixEnd 为 0 ,初始化 next 数组的第 0 位元素为 0
- 因为以第 0 位为结尾的子串没有前缀,也没有后缀,最大相同前后缀长度为 0
遍历以 suffixEnd 为结尾的子串(即,遍历 suffixEnd ),执行以下操作:
-
若
s[prefixEnd] != s[suffixEnd],即,前缀末尾字符与后缀末尾字符不相同,执行循环(直到s[prefixEnd] == s[suffixEnd]或者prefixEnd == 0):收缩前缀,将前缀末尾回退到next[prefixEnd - 1]位置 -
若
s[prefixEnd] == s[suffixEnd],即,前缀末尾字符与后缀末尾字符相同,执行prefixEnd++,将前缀末尾向右移- 向右移有两方面的原因:1)当前找到前缀的长度为
prefixEnd + 1,故,最长相同前后缀的长度为prefixEnd + 1;2)对于suffixEnd下一位的 next 数组元素而言,其最大取值为next[suffixEnd] + 1(前缀表的性质: ,当 时,等号成立)
- 向右移有两方面的原因:1)当前找到前缀的长度为
-
更新 next 数组:执行
next[suffixEnd] = prefixEnd
# 代码实现
void getNext(vector<int>& next, const string& s) { | |
int prefixEnd = 0; //prefixEnd 表示前缀的末尾(前缀从第 0 位开始) | |
next[0] = 0; | |
// 计算最长相同前后缀的长度 | |
for(int suffixEnd = 1; suffixEnd < s.size(); suffixEnd++) { //suffixEnd 表示后缀的末尾(后缀从第 1 位开始) | |
// 比较前缀末尾字符与后缀末尾字符 | |
while (prefixEnd > 0 && s[suffixEnd] != s[prefixEnd]) { //prefixEnd 大于 0 ,因为后续要将 prefixEnd - 1 作为下标 | |
prefixEnd = next[prefixEnd - 1]; // 前缀末尾与后缀末尾不相同,要将前缀收缩到与后缀相同的情况 | |
} | |
if (s[suffixEnd] == s[prefixEnd]) { | |
prefixEnd++; // 前缀末尾字符与后缀末尾字符相同,前缀长度为 prefixEnd + 1,将 prefixEnd 右移 | |
} | |
next[suffixEnd] = prefixEnd; // 以 suffixEnd 为结尾的子串的最长相同前后缀的长度为 prefixEnd | |
} | |
} |
建议结合实例来理解 next 数组的获取过程,例如,考虑字符串 "aabaaf" 的 next 数组
# 利用前缀表进行字符串匹配
这里介绍如何使用 next 数组(直接利用上述构造的 next 数组),完成模式串 t 与文本串 s 的匹配
# 算法流程
定义 j 指向模式串 t 的起始位置
int j = 0;
定义 i 指向文本串 s 的起始位置, i 从 0 开始遍历文本串
-
若
s[i] != t[j],需要从 next 数组中寻找下一个位置进行匹配while (j > 0 && s[i] != t[j]) j = next[j - 1]; -
若
s[i] == t[j],将i和j同时向右移动一位if (s[i] == t[j]) j++; -
若
j最终指向模式串t的尾后,说明,模式串t完全匹配文本串s
# 代码实现
bool IsSubString (string s, string t) { | |
if (s.size() == 0) return false; | |
vector<int> next(t.size()); | |
getNext(next, t); | |
int j = 0; | |
for (int i = 0; i < s.size(); i++) { | |
while (j > 0 && s[i] != t[j]) | |
j = next[j - 1]; | |
if (s[i] == t[j]) | |
j++; | |
if (j == t.size) | |
return true; | |
} | |
return false; | |
} |
具体实例可见 LeetCode 28. 实现 strStr ()
参考资料: