# LeetCode 100. 相同二叉树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:

输入:p = [1,2,3], q = [1,2,3]
输出:true
示例 2:

输入:p = [1,2], q = [1,null,2]
输出:false
示例 3:

输入:p = [1,2,1], q = [1,1,2]
输出:false
提示:
- 两棵树上的节点数目都在范围 内
-
Node.val
# 思路
如果两棵树的所有节点都相同,则这两棵二叉树相同
因此,判断两棵二叉树是否相同的步骤可分为:
- 判断根节点的值是否相等
- 判断左子树是否相同
- 判断右子树是否相同
解法类似于 LeetCode 101. 对称二叉树
# Method 1: 递归
算法思路:
-
定义递归函数:检查以
p、q为根节点的两棵是否相同 -
递归函数的内部,做以下判断:
- 若
p与q同时为空,则两树相同 - 若
p与q不同时为空,则两树不同 - 若
p与q的值不相等,则两树相同 - 若
p的左子树 与q的左子树不相同,则两树不同 - 若
p的右子树 与q的右子树不相同,则两树不同
- 若
代码实现:
bool isSameTree(TreeNode* p, TreeNode* q) { | |
if (!p && !q) return true; | |
if (!p || !q) return false; | |
if (p->val != q->val) return false; | |
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right); | |
} |
时间复杂度:,其中,, 分别是两棵二叉树的节点数
空间复杂度:,这里考虑了递归使用的栈空间
- 递归调用的层数不会超过较小的二叉树的最大高度
- 最坏情况下,二叉树的高度等于节点数
# Method 2: 迭代
本题也可以使用迭代法来显式地维护 Method 1 中调用的栈
这里利用 栈 来存放待访问的节点(也可以使用队列,区别仅在于节点的访问顺序)
# 写法一
类似于 LeetCode 101. 对称二叉树 的 Method 2
代码实现:
bool isSameTree(TreeNode* p, TreeNode* q) { | |
stack<TreeNode*> stk; | |
stk.push(q); | |
stk.push(p); | |
TreeNode *u = nullptr, *v = nullptr; | |
while (!stk.empty()) { | |
u = stk.top(); | |
stk.pop(); | |
v = stk.top(); | |
stk.pop(); | |
if ((u == nullptr) && (v == nullptr)) continue; | |
if ((u == nullptr) || (v == nullptr)) return false; | |
if (u->val != v->val) return false; | |
stk.push(v->right); | |
stk.push(u->right); | |
stk.push(v->left); | |
stk.push(u->left); | |
} | |
return true; | |
} |
若采用 队列 来实现迭代法,将上述代码中的 栈(及其成员函数)替换为 队列(及其成员函数)即可
# 写法二
为降低算法复杂度,可以仅将非空节点入栈
因此,在将两棵树的子节点入栈前,须对两棵树的结构进行判断
算法思路:
- 定义一个栈,若
p与q非空,将其入栈 - 执行循环,直到栈为空:
- 从栈中取出两个节点,记作
u和v - 判断
u和v的值是否相等 - 判断
u的右子节点 和v的右子节点 是否为空- 如果有且仅有一个为空,则说明
u和v的右子树结构不同,返回false - 如果均不为空,则将其入栈,以进一步判断右子树是否相同
- 如果有且仅有一个为空,则说明
- 判断
u和v的左子节点是否为空,类似于上一步
- 从栈中取出两个节点,记作
- 循环结束时,栈为空,且不存在不相同的节点,返回
true
其中,当 u 和 v 的右子节点均为空时,对应的右子树相同,无需再将其入栈,类似地,当 u 和 v 的左子节点均为空时,也无需将其入栈
代码实现:
bool isSameTree(TreeNode* p, TreeNode* q) { | |
if (!p && !q) return true; | |
if (!p || !q) return false; | |
stack<TreeNode*> stk; | |
stk.push(q); | |
stk.push(p); | |
TreeNode *u = nullptr, *v = nullptr; | |
while (!stk.empty()) { | |
u = stk.top(); | |
stk.pop(); | |
v = stk.top(); | |
stk.pop(); | |
if (u->val != v->val) return false; | |
if ((u->right == nullptr) ^ (v->right == nullptr)) //u 或 v 不存在右子节点 | |
return false; | |
if ((u->left == nullptr) ^ (v->left == nullptr)) //u 或 v 不存在左子节点 | |
return false; | |
if (v->right) stk.push(v->right); // 将非空的右子节点入栈 | |
if (u->right) stk.push(u->right); | |
if (v->left) stk.push(v->left); // 将非空的左子节点入栈 | |
if (u->left) stk.push(u->left); | |
} | |
return true; | |
} |
时间复杂度:,其中,, 分别是两棵二叉树的节点数
空间复杂度:
参考:力扣官方题解:相同的树
# LeetCode 101. 对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:

输入:root = [1,2,2,3,4,4,3]
输出:true
示例 2:

输入:root = [1,2,2,null,3,null,3]
输出:false
提示:
- 树中节点数目在范围 内
-
Node.val
进阶:你可以运用递归和迭代两种方法解决这个问题吗?
# 思路
如果一棵树的左子树与右子树对称,那么这棵树就是对称的
进一步地分析,子树 A1 与子树 A2 对称,需要满足以下条件:
- A1 的根节点值 等于 A2 的根节点值
- A1 的左子树 与 A2 的右子树 对称
- A1 的右子树 与 A2 的左子树 对称
如下图所示,检查二叉树对称性的步骤可分为:
- 检查 B 与 C 的值是否相等
- 检查 D 与 G 的值是否相等
- 检查 E 与 F 的值是否相等

# Method 1: 递归
算法思路:
-
定义一个递归函数,函数传入两个参数:
- 指针
l:指向左侧的子树 A1 - 指针
r:指向右侧的子树 A2
- 指针
-
递归函数的作用:检查子树 A1 与 A2 是否对称
-
递归函数的内部,做以下判断:
- 若
l与r同时为空,则 A1 与 A2 对称 - 若
l与r不同时为空,则 A1 与 A2 不对称 - 若
l与r的值不相等,则 A1 与 A2 不对称 - 若
l的左子树 与r的右子树不对称,则 A1 与 A2 不对称 - 若
l的右子树 与r的左子树不对称,则 A1 与 A2 不对称
- 若
代码实现:
bool check(TreeNode* l, TreeNode* r) { // 检查 l 与 r 及其子树是否对称 | |
if (l == nullptr && r == nullptr) return true; //l 与 r 均为空 | |
if (l == nullptr || r == nullptr) return false; //l 为空,或,r 为空 | |
if (l->val != r->val) return false; // 检查 l 与 r 是否对称 | |
return check(l->left, r->right) && check(l->right, r->left); // 检查 l 与 r 的子树是否对称 | |
} | |
bool isSymmetric(TreeNode* root) { | |
if (root == nullptr) return true; | |
return check(root->left, root->right); | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:,这里考虑了递归使用的栈空间
# Method 2: 迭代
对于二叉树的前序、中序、后序遍历,我们可以使用迭代法来显式地维护递归调用的栈
类似地,本题可以定义一个 队列 来显式地维护 Method 1 中递归调用的栈,以检查两棵子树的对称性
这里为了能够逐层遍历,采用的是 队列 来实现迭代法,事实上,也可以使用 栈 来实现
算法流程:
- 定义一个队列,并将根节点
root的两个子节点入队 - 执行循环,直到队列为空:
- 从队列中取出两个节点,记作
u和v(类似于 Method 1 中的 指针l和r,分别指向子树 A1 和 A2) - 若
u和v均为空,则跳过本次循环 - 若
u和v中有且仅有一个为空,则子树不对称,返回false - 若
u和v均不为空,判断u与v的值是否相等,若不相等,则返回false - 将
u的左子节点、v的右子节点依次入队 - 将
u的右子节点、v的左子节点依次入队
- 从队列中取出两个节点,记作
- 循环结束时,队列为空,不存在不对称的子树,返回
true
代码实现:
bool isSymmetric(TreeNode* root) { | |
if (root == nullptr) return true; | |
queue<TreeNode*> que; | |
que.push(root->left); | |
que.push(root->right); | |
TreeNode *u = new TreeNode(0), *v = new TreeNode(0); | |
while (!que.empty()) { | |
u = que.front(); // 指向子树 A1 | |
que.pop(); | |
v = que.front(); // 指向子树 A2 | |
que.pop(); | |
if (!u && !v) continue; // A1 与 A2 同时为空 | |
if (!u || !v) return false; // A1 与 A2 不同时为空 | |
if (u->val != v->val) return false; // A1 与 A2 的根节点值不相等 | |
que.push(u->left); // A1 的左子树 | |
que.push(v->right); // A2 的右子树 | |
que.push(u->right); // A1 的右子树 | |
que.push(v->left); // A2 的左子树 | |
} | |
return true; | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:
# LeetCode 102. 二叉树的层序遍历
LeetCode 102. Binary Tree Level Order Traversal
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
提示:
- 树中节点数目在范围 内
-
Node.val
# 思路
逐层遍历二叉树,其中,每层按从左到右顺序遍历
由于队列具有先进先出特性,本题可利用队列来存放 待访问的节点,即,按从左到右的顺序将待访问的节点依次加入到队列中
注意本题要求输出一个二维数组,其中,二维数组中的每一个一维数组,表示 二叉树每一层上所有节点的值。因此,一维数组的长度 即为 对应层上的二叉树节点数,亦为 上一层访问结束后的队列长度
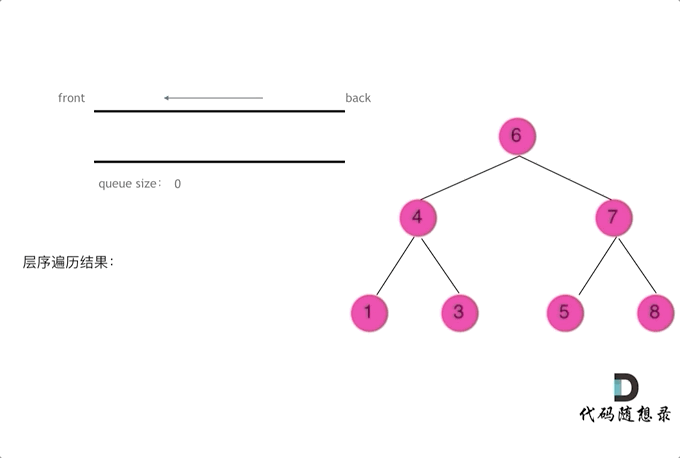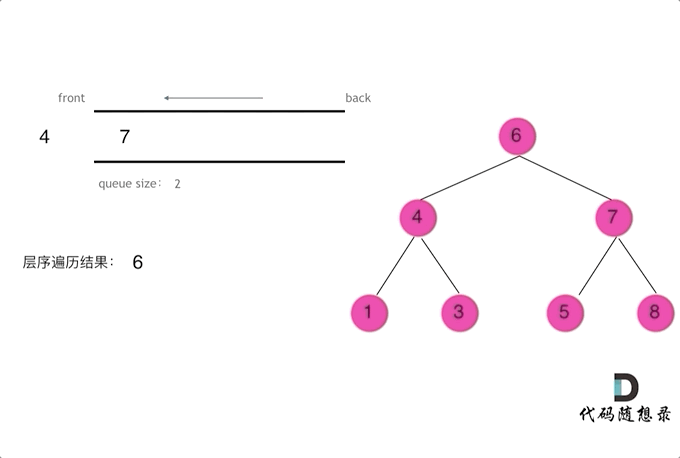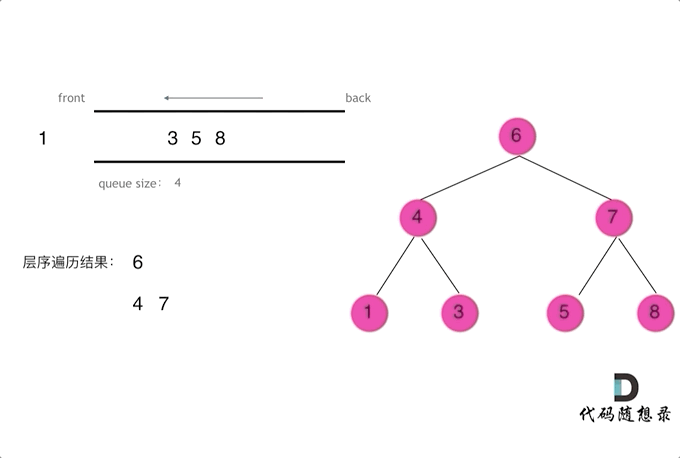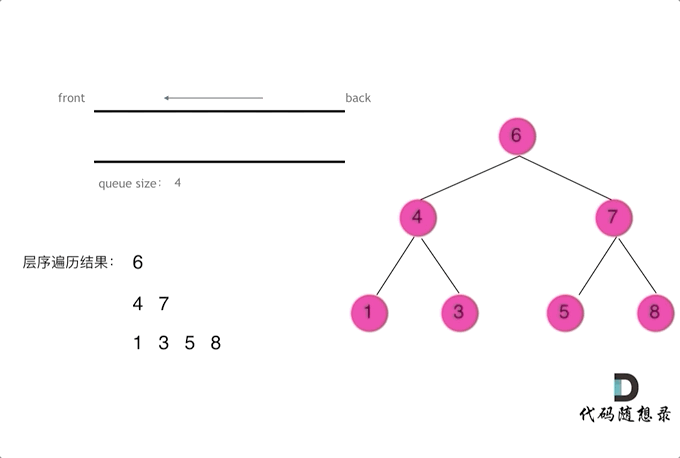
# Method: 广度优先搜索
算法思路:
-
将根节点入队
-
当队列不为空,执行以下循环:
- 求当前队列的长度
- 依次从队列中取 个元素:
- 读取其值,将值临时存放到一维数组
tmp中 - 将非空的左、右子节点依次入队
- 读取其值,将值临时存放到一维数组
- 将一维数组
tmp添加到目标数组res
普通的广度优先搜索每次只取 1 个元素拓展,而这里每次取 个元素,即,第 次迭代就得到了二叉树的第 层的 个元素
代码实现:
vector<vector<int>> levelOrder(TreeNode* root) { | |
vector<vector<int>> res; | |
queue<TreeNode*> que; // 队列存放的是待展开的二叉树节点 | |
if (root != nullptr) que.push(root); | |
while (!que.empty()) { | |
vector<int> tmp; | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
tmp.push_back(node->val); | |
if (node->left != nullptr) que.push(node->left); | |
if (node->right != nullptr) que.push(node->right); | |
} | |
res.push_back(tmp); | |
} | |
return res; | |
} |
时间复杂度:,每个点入队出队各一次,其中 为树的所有节点的个数
空间复杂度:,队列中元素的个数不超过 个
# LeetCode 104. 二叉树的最大深度
LeetCode 104. Maximum Depth of Binary Tree
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明:叶子节点是指没有子节点的节点。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:3
示例 2:
输入:root = [1,null,2]
输出:2
提示:
- 二叉树的节点数在范围 内
-
Node.val
# 思路
二叉树的深度是从上往下数,而高度是从下往上数
即,按前序遍历顺序求的是二叉树的深度,按后序遍历顺序求的是二叉树的高度。具体可参考 LeetCode 110. 平衡二叉树 中的概念辨析
# Method 1: 递归
本题可通过后序遍历来计算根节点的高度,从而得到二叉树的最大深度(根节点的高度,即为二叉树的最大深度)
算法思路:
-
若已知左子树和右子树的高度分别为 和 ,则二叉树的高度为
-
左子树与右子树的高度可通过同样方式获得,即,递归
-
递归的终止条件为:节点为空
代码实现:
int maxDepth(TreeNode* root) { | |
if (root == nullptr) return 0; // 当 root 为空时,深度为 0 | |
int l = maxDepth(root->left); // 左子树的高度 | |
int r = maxDepth(root->right); // 右子树的高度 | |
int ans = 1 + max(l, r); | |
return ans; | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:,其中, 为二叉树的最大深度(这里考虑了递归所需的栈空间)
本题也可以使用前序遍历计算节点的深度,节点深度的最大值即为二叉树的最大深度。具体可参考 代码随想录:二叉树的最大深度
# Method 2: 层序遍历
算法思路:
- 利用队列存储待访问的节点,与 LeetCode 102. 二叉树的层序遍历 类似
- 逐层遍历,遍历的层数就是二叉树的最大深度(即,从根节点到最底层节点所经历的层数)
代码实现:
int maxDepth(TreeNode* root) { | |
int ans = 0; // 二叉树的深度 | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
TreeNode* tmp = que.front(); | |
que.pop(); | |
if (tmp->left) que.push(tmp->left); | |
if (tmp->right) que.push(tmp->right); | |
} | |
ans++; | |
} | |
return ans; | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:
# LeetCode 559. N 叉树的最大深度
LeetCode 559. Maximum Depth of N-ary Tree
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:3
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:5
提示:
- 树的深度不超过
- 树的节点数在范围 内
# Method 1: 递归
代码实现:
int maxDepth(Node* root) { | |
if (!root) return 0; | |
int depth = 0; | |
for (int i = 0; i < root->children.size(); i++) { | |
int temp = maxDepth(root->children[i]); // 第 i 棵子树的最大深度 | |
depth = max(depth, temp); // 所有子树的最大深度 | |
} | |
return 1 + depth; // 以 root 为根节点的树的最大深度 | |
} |
时间复杂度:,其中, 为 N 叉树的节点数
空间复杂度:,其中, 为 N 叉树的最大深度(这里考虑了递归所需的栈空间)
# Method 2: 层序遍历
代码实现:
int maxDepth(Node* root) { | |
int depth = 0; | |
queue<Node*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
depth++; | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
Node* tmp = que.front(); | |
que.pop(); | |
for (int j = 0; j < tmp->children.size(); j++) | |
if (tmp->children[j]) que.push(tmp->children[j]); | |
} | |
} | |
return depth; | |
} |
时间复杂度:,其中, 为 N 叉树的节点数
空间复杂度:
# LeetCode 105. 从前序与中序遍历序列构造二叉树
105. Construct Binary Tree from Preorder and Inorder Traversal
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入:preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:preorder = [-1], inorder = [-1]
输出:[-1]
提示:
-
preorder.length inorder.length == preorder.length-
preorder[i],inorder[i] preorder和inorder均无重复元素inorder的每个元素均出现在preorderpreorder保证为二叉树的前序遍历序列inorder保证为二叉树的中序遍历序列
# 思路
根据前序遍历数组的第一个元素来确定根节点
在中序遍历数组中找到根节点,根节点左侧、右侧分别为左子树、右子树的中序遍历序列
根据左子树的中序遍历序列长度,确定左子树、右子树的前序遍历序列
- 树的中序遍历序列长度等于前序遍历序列长度,并且同一棵树的节点在遍历数组中连续
依此类推,最终可确定每个节点的左、右子节点
# Method: 递归
算法思路:类似于 LeetCode 106. 从中序与后序遍历序列构造二叉树
分割数组时,坚持区间不变量原则,左闭右开,或者左闭右闭
代码实现:
TreeNode* traversal(vector<int>& preorder, vector<int>& inorder, int preorderBegin, int preorderEnd, int inorderBegin, int inorderEnd) { | |
if (preorderBegin == preorderEnd) return nullptr; | |
// 根节点 | |
int rootValue = preorder[preorderBegin]; | |
TreeNode *root = new TreeNode(rootValue); | |
// 中序遍历分界线 | |
int delimiterIndex = inorderBegin; | |
for (; delimiterIndex < inorderEnd; delimiterIndex++) | |
if (inorder[delimiterIndex] == rootValue) break; | |
// 左子树的节点数 | |
int leftSize = delimiterIndex - inorderBegin; | |
// 左子树的前序区间:[preorderBegin + 1, preorderBegin + 1 + leftSize) | |
// 左子树的中序区间:[inorderBegin, delimiterIndex) | |
root->left = traversal(preorder, inorder, preorderBegin + 1, preorderBegin + 1 + leftSize, inorderBegin, delimiterIndex); | |
// 右子树的前序区间:[preorderBegin + 1 + leftSize, preorderEnd) | |
// 右子树的中序区间:[delimiterIndex + 1, inorderEnd) | |
root->right = traversal(preorder, inorder, preorderBegin + 1 + leftSize, preorderEnd, delimiterIndex + 1, inorderEnd); | |
return root; | |
} | |
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) { | |
return traversal(preorder, inorder, 0, preorder.size(), 0, inorder.size()); | |
} |
时间复杂度:,其中 为二叉树的节点数
- 每个节点都将调用一次
traversal函数,时间复杂度为 - 每次调用
traversal函数时,需要找到根节点在中序遍历数组中的位置- 平均情况下,时间复杂度为
- 最坏情况下,时间复杂度为
# 优化
可以考虑使用哈希表来快速定位根节点在中序遍历数组中的位置
key表示一个元素(节点的值),value表示其在中序遍历序列中的出现位置
具体实现:
-
定义全局变量
unordered_map<int, int> index;
-
在
buildTree函数中,构造哈希映射for (int i = 0; i < n; ++i) {
index[inorder[i]] = i;
} -
在递归函数
traversal中,使用哈希表查询根节点int delimiterIndex = index[preorder[preorderBegin]]; //preorder 首元素为根节点的值
优化后的算法时间复杂度为
# LeetCode 106. 从中序与后序遍历序列构造二叉树
106. Construct Binary Tree from Inorder and Postorder Traversal
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:

输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
-
inorder.length postorder.length == inorder.length-
inorder[i],postorder[i] inorder和postorder均无重复元素postorder的每个元素均出现在inorderinorder保证为二叉树的中序遍历序列postorder保证为二叉树的后序遍历序列
# 思路
根据后序遍历的最后一个元素来确定根节点
在中序遍历中找到根节点,得到左子树的中序遍历、右子树的中序遍历
- 依据:在中序遍历的数组中,根节点左侧为左子树,右侧为右子树
在后序遍历中分别找到左子树所有节点、右子树所有节点,即可得到左子树、右子树的后序遍历
- 依据:后序遍历的数组大小等于中序的数组大小,同一棵树的节点在遍历数组中连续
依此类推,最终可确定每个节点的左、右子节点
# Method: 递归
算法流程:
-
若二叉树的中序遍历数组为空,当前树为空
-
若不为空,取后序数组的最后一个元素作为根节点
-
找到根节点在中序数组的位置,作为切割点
-
切割中序数组,分成中序左数组、中序右数组
-
根据中序左数组、中序右数组的大小来切割后序数组,将其分成后序左数组、后序右数组
-
递归处理左子树和右子树
分割数组时,坚持区间不变量原则,左闭右开,或者左闭右闭
为降低时空间复杂度,通过使用左子树、右子树节点在数组 inorder 和 postorder 的下标索引,表示左子树、右子树的中序、后序遍历的结果数组
代码实现:
// 根据中序区间和后序区间确定根节点及左右子树 | |
// 中序区间 [inorderBegin, inorderEnd),后序区间 [postorderBegin, postorderEnd) | |
TreeNode* traversal(vector<int> &inorder, vector<int> &postorder, int inorderBegin, int inorderEnd, int postorderBegin, int postorderEnd) { | |
if (inorderBegin == inorderEnd) return nullptr; // 空数组,二叉树为空 | |
int rootValue = postorder[postorderEnd - 1]; // 后序遍历的最后一个元素为根节点 | |
TreeNode *root = new TreeNode(rootValue); // 根节点 | |
if (inorder.size() == 1) return root; | |
// 找到根节点在中序遍历数组中的位置,即,左、右子树的分界线 | |
int delimiterIndex; | |
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd ; delimiterIndex++) { | |
if (inorder[delimiterIndex] == rootValue) break; | |
} | |
// 切割中序数组 | |
// 左子树的中序遍历数组,对应在 inorder 中的索引为 [leftInorderBegin, leftInorderEnd) | |
int leftInorderBegin = inorderBegin; | |
int leftInorderEnd = delimiterIndex; | |
// 右子树的中序遍历数组,对应在 inorder 中的索引为 [rightInorderBegin, rightInorderEnd) | |
int rightInorderBegin = delimiterIndex + 1; // 需排除根节点 | |
int rightInorderEnd = inorderEnd; | |
// 切割后序数组 | |
// 左子树的后序遍历数组,对应在 postorder 中的索引为 [leftPostorderBegin, leftPostorderEnd) | |
int leftPostorderBegin = postorderBegin; | |
int leftPostorderEnd = postorderBegin + (leftInorderEnd - leftInorderBegin); | |
// 右子树的后序遍历数组,对应在 postorder 中的索引为 [rightPostorderBegin, rightPostorderEnd) | |
int rightPostorderBegin = postorderBegin + (leftInorderEnd - leftInorderBegin); | |
int rightPostorderEnd = postorderEnd - 1; // 需排除根节点 | |
// 递归到左子树(确定 root 的左子节点指针) | |
root->left = traversal(inorder, postorder, leftInorderBegin, leftInorderEnd, leftPostorderBegin, leftPostorderEnd); | |
// 递归到右子树(确定 root 的右子节点指针) | |
root->right = traversal(inorder, postorder, rightInorderBegin, rightInorderEnd, rightPostorderBegin, rightPostorderEnd); | |
return root; | |
} | |
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { | |
if (inorder.size() == 0) return nullptr; | |
return traversal(inorder, postorder, 0, inorder.size(), 0, postorder.size()); | |
} |
时间复杂度:,其中 为二叉树的节点数
- 每个节点都将调用一次
traversal函数,时间复杂度为 - 每次调用
traversal函数时,需要找到根节点在中序遍历数组中的位置- 平均情况下,时间复杂度为
- 最坏情况下,时间复杂度为
空间复杂度:,考虑了递归使用的栈空间
简化版:
TreeNode* traversal(vector<int> &inorder, vector<int> &postorder, int inorderBegin, int inorderEnd, int postorderBegin, int postorderEnd) { | |
if (inorderBegin == inorderEnd) return nullptr; // 空数组,二叉树为空 | |
int rootValue = postorder[postorderEnd - 1]; // 后序遍历的最后一个元素为根节点 | |
TreeNode *root = new TreeNode(rootValue); // 根节点 | |
if (inorder.size() == 1) return root; | |
// 找到根节点在中序遍历数组中的位置 | |
int delimiterIndex; | |
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd ; delimiterIndex++) | |
if (inorder[delimiterIndex] == rootValue) break; | |
// 左子树节点数 | |
int leftSize = delimiterIndex - inorderBegin; | |
// 递归到左子树 | |
root->left = traversal(inorder, postorder, inorderBegin, delimiterIndex, postorderBegin, postorderBegin + leftSize); | |
// 递归到右子树 | |
root->right = traversal(inorder, postorder, delimiterIndex + 1, inorderEnd, postorderBegin + leftSize, postorderEnd - 1); | |
return root; | |
} | |
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { | |
if (inorder.size() == 0) return nullptr; | |
return traversal(inorder, postorder, 0, inorder.size(), 0, postorder.size()); | |
} |
# 优化
另外,可以考虑使用哈希表来快速定位根节点
key表示一个元素(节点的值),value表示其在中序遍历序列中的出现位置- 在调用递归函数前,先对中序遍历序列进行一遍扫描,构造出哈希表
- 以后只需要 的时间就可以对中序遍历中的根节点进行定位
具体实现:
-
定义全局变量
unordered_map<int, int> index;
-
在
buildTree函数中构造哈希映射for (int i = 0; i < n; ++i) {
index[inorder[i]] = i;
} -
在递归函数
traversal中使用哈希表查询根节点int delimiterIndex = index[postorder[postorderEnd]]; //postorder 最后元素为根节点的值
优化后的算法时间复杂度为
# LeetCode 107. 二叉树的层序遍历 II
LeetCode 107. Binary Tree Level Order Traversal II
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[15,7],[9,20],[3]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
提示:
- 树中节点数目在范围 内
-
Node.val
# 思路
与 LeetCode 102. 二叉树的层序遍历 不同,本题的遍历是从二叉树底层向上遍历
# Method: 广度优先搜索
算法流程:
-
按照 LeetCode 102. 二叉树的层序遍历 算法自上而下遍历二叉树
-
反转目标数组
代码实现:
vector<vector<int>> levelOrderBottom(TreeNode* root) { | |
vector<vector<int>> res; | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
vector<int> tmp; | |
for (int i = 0; i < size; i++) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
tmp.push_back(node->val); | |
if (node->left) que.push(node->left); | |
if (node->right) que.push(node->right); | |
} | |
res.push_back(tmp); | |
} | |
reverse(res.begin(), res.end()); // 反转二维数组 | |
return res; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# LeetCode 108. 将有序数组转换为二叉搜索树
108. Convert Sorted Array to Binary Search Tree
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:

输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案

示例 2:

输入:nums = [1,3]
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树
提示:
-
nums.length -
nums[i] nums按 严格递增 顺序排列
# 思路
注意本题的数组 nums 为严格递增的有序序列
取数组最中间元素 mid 作为二叉树的根节点, mid 左侧所有元素作为左子树, mid 右侧所有元素作为右子树
于是,左子树所有节点值小于根节点,右子树所有节点值大于根节点,即,满足二叉搜索树的要求
并且,左子树、右子树的最大高度差不超过 1 (当数组元素为偶数时,高度差最大,值为 1),即,满足平衡二叉树的要求
- 若取
mid = left + (right - left) / 2;,左侧元素个数比右侧少 1 - 若取
mid = left + (right - left + 1) / 2;,左侧元素个数比右侧多 1
注意:在分割数组时需要坚持不变量原则,即,预先定义有效区间为 左闭右闭
[left, right](或者 左闭右开[left, right))
由于选择根节点的方式不同,构造出的二叉搜索树也就不同,因此,本题存在多解
# Method: 递归
算法思路:总是选择中间位置左边的数字作为根节点,即,取 mid = left + (right - left) / 2;
这里采用 左闭右闭 原则:从 nums 数组中取出索引为 [left, right] 的所有元素,将其构建为一棵平衡二叉搜索树
代码实现:
TreeNode* buildTree(vector<int> &nums, int left, int right) { // 将数组索引为 [left, right] 的元素建成一棵二叉搜索树 | |
if (left > right) return nullptr; // 没有节点需要建立 | |
int mid = left + (right - left) / 2; // 取 [left, right] 区间中点对应元素值作为根节点值 | |
TreeNode *node = new TreeNode(nums[mid]); // 根节点 | |
node->left = buildTree(nums, left, mid - 1); // 左子树 | |
node->right = buildTree(nums, mid + 1, right); // 右子树 | |
return node; | |
} | |
TreeNode* sortedArrayToBST(vector<int>& nums) { | |
return buildTree(nums, 0, nums.size() - 1); | |
} |
时间复杂度:,其中 是数组的长度
空间复杂度:,递归的最大深度为
# LeetCode 110. 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
一棵高度平衡二叉树定义为:一个二叉树每个节点的左右两个子树的高度差的绝对值不超过 1 。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:true
示例 2:

输入:root = [1,2,2,3,3,null,null,4,4]
输出:false
示例 3:
输入:root = []
输出:true
提示:
- 树中的节点数在范围 内
-
Node.val
# 概念辨析
# 节点的深度与高度
深度是从上往下数,而高度是从下往上数
-
维基百科
- 节点的深度:从根节点到该节点路径上的边的条数
- 结点的高度:从该节点到叶节点路径上的边的条数
-
Leetcode
- 节点的深度:从根节点到该节点路径上的节点个数
- 结点的高度:从该节点到叶节点路径上的节点个数
按照维基百科的定义,根节点的深度为 0 ;按照 Leetcode 的定义,根节点的深度为 1
这里以 Leetcode 定义为准
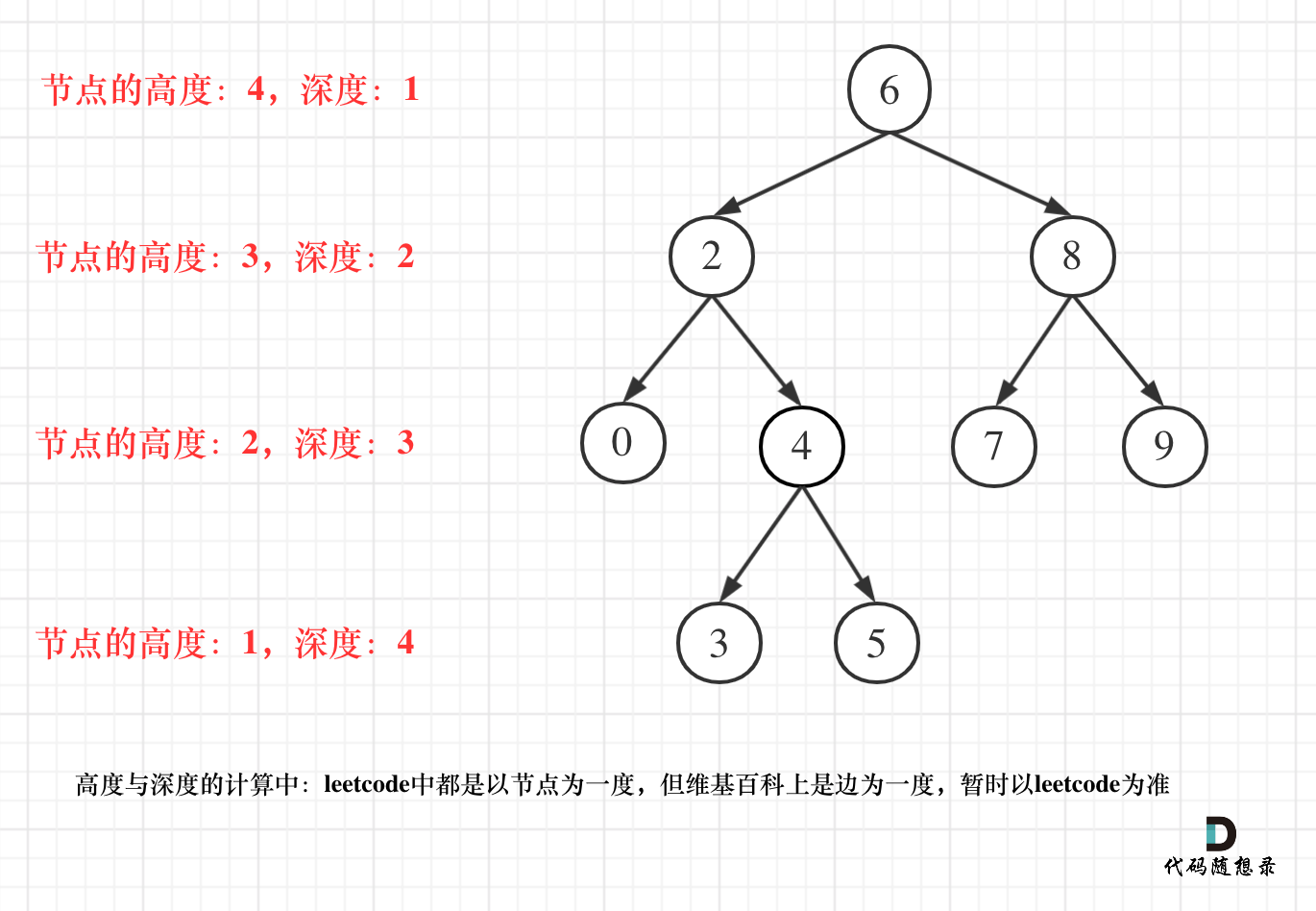
对于具有相同深度的节点,它们的高度不一定相同,这取决于它们下面的叶结点的深度
计算节点的深度,按照从上往下的顺序去遍历子节点,需要采用前序遍历
计算节点的高度,按照从下往上的顺序去遍历,需要采用后序遍历
# 树的深度与高度
二叉树的深度:所有节点中最深节点的深度,即,二叉树最底层节点的深度
二叉树的高度:根节点的高度
二叉树的 深度 与 高度 在数值上相等
因此,计算二叉树的深度(高度),可按照从上往下的顺序(前序遍历、层序遍历)计算最底层节点的深度,也可按照从下往上的顺序(后序遍历)计算根节点的高度
# 思路
按照本题的提示 “若每个节点的左子树与右子树的高度差不超过 1 ,该二叉树为平衡二叉树” ,可以通过计算每个节点左右子树的高度差来判断是否为平衡二叉树
一棵二叉树为平衡二叉树,当且仅当其所有子树都是平衡二叉树
因此,可以使用递归来判断。其中,递归可以按照 自顶向下 的顺序,也可以按照 自底向上 的顺序
# Method 1: 自顶向下
算法思路:
- 定义一个递归函数
height,用于计算节点root的高度 - 从根节点开始遍历节点
- 分别调用
height函数计算左、右子树的高度 - 若左右子树的高度差的绝对值大于 1,二叉树不是平衡二叉树,返回
false - 若左右子树的高度差的绝对值不超过 1,分别递归到左、右子节点(分别判断以左子节点为根节点、以右子节点为根节点的二叉树是否为平衡二叉树)
- 分别调用
代码实现:
int height(TreeNode* root) { // 计算 root 节点的高度 | |
if (root == nullptr) return 0; | |
return 1 + max(height(root->left), height(root->right)); | |
} | |
bool isBalanced(TreeNode* root) { // 判断以 root 为根节点的树是否为平衡二叉树 | |
if (!root) return true; | |
if (abs(height(root->left) - height(root->right)) > 1) //root 左右子树的高度差大于 1 | |
return false; | |
return isBalanced(root->left) && isBalanced(root->right); // 递归到左右子节点 | |
} |
时间复杂度:,其中 是二叉树的节点数
- 最坏情况下,二叉树为满二叉树,需要遍历满二叉树的所有节点,时间复杂度为
- 对于任意节点
p,如果它的高度为 ,则height(p)最多会被调用 次(被p及其祖先节点调用),因此节点p的计算时间复杂度为 ,其中,, 是二叉树的最大高度- 平均情况下,,此时,总的时间复杂度为
- 最坏情况下,二叉树呈链状,,此时,总的时间复杂度为
空间复杂度:,不考虑递归调用栈
# Method 2: 自底向上
注意,在上述方法中,对于每个节点, height 函数会被调用多次,故而时间复杂度较高
可以采用自底向上的顺序,对于每个节点, height 函数仅被调用 1 次
算法思路:
-
定义
height函数,输入参数为root,返回参数为int型的数- 分别递归到左子树、右子树(即,调用
height(root->left)和height(root->right)),并记录其返回值 - 判断左子树、右子树是否平衡
- 若否,返回
-1
- 若否,返回
- 判断以当前
root节点为根节点的树是否平衡- 若是,返回
root的高度 - 否则,返回
-1
- 若是,返回
- 分别递归到左子树、右子树(即,调用
-
若
height函数返回值为-1,二叉树不是平衡二叉树,isBalanced函数返回false
代码实现:
int height(TreeNode* root) { // 若二叉树为平衡二叉树,返回 root 的高度;否则,返回 -1 | |
if (!root) return 0; | |
int leftHight = height(root->left); | |
int rightHight = height(root->right); | |
if (leftHight == -1 || rightHight == -1 || abs(leftHight - rightHight) > 1) // 非平衡 | |
return -1; // 返回 -1 | |
return 1 + max(leftHight, rightHight); // 平衡,返回高度 | |
} | |
bool isBalanced(TreeNode* root) { | |
if (height(root) == -1) return false; | |
return true; | |
} |
时间复杂度:,其中, 为二叉树的节点数
- 最坏情况下,需要遍历二叉树的所有节点,时间复杂度为
- 每个节点仅计算一次高度,只进行一次 是否平衡 的判断,时间复杂度为
空间复杂度:,不考虑递归调用栈
参考:力扣官方题解:平衡二叉树
# LeetCode 111. 二叉树的最小深度
LeetCode 111. Minimum Depth of Binary Tree
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:2
示例 2:
输入:root = [2,null,3,null,4,null,5,null,6]
输出:5
提示:
- 树中节点数的范围在 内
-
Node.val
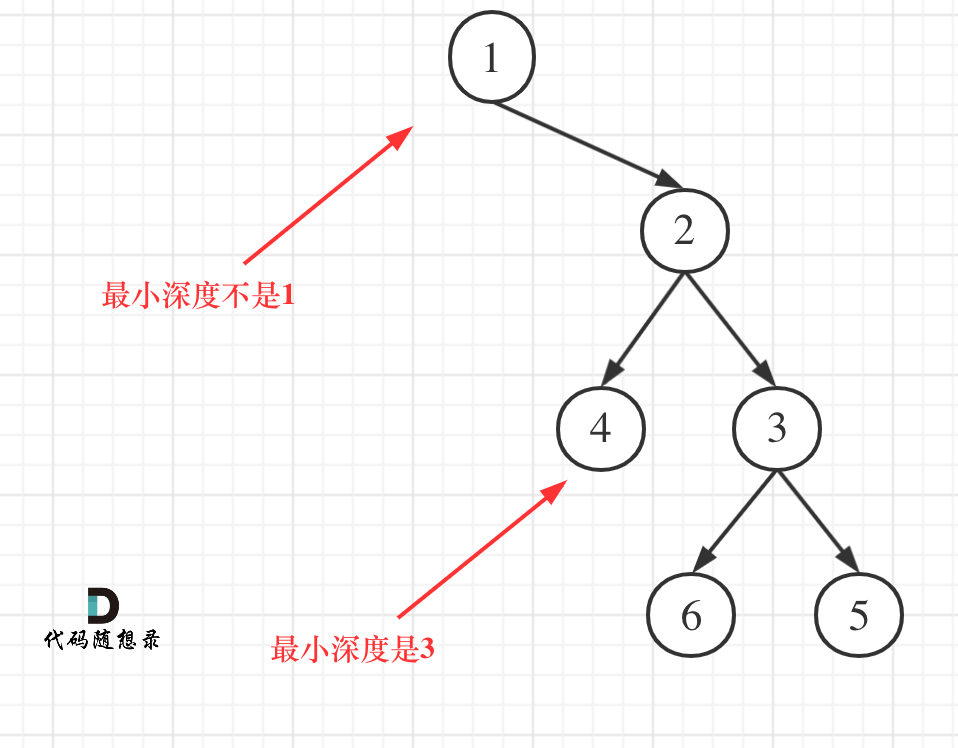
# 思路
最小深度:从根节点到最近叶节点的最短路径上的节点数量
注意:叶节点是指左右子节点均为空的节点
# Method 1: 递归
递归函数:
- 输入参数:
root - 函数返回值:以
root为根节点的树的最小深度
# 写法一
递归终止条件:
-
若左子树与右子树均不为空,返回
1 + min (左子树最小深度、右子树最小深度) -
若左子树为空、右子树不为空,返回
1 + 右子树的最小深度 -
若左子树不为空、右子树为空,返回
1 + 左子树的最小深度 -
若右子树与右子树均为空,节点为叶节点,返回
1
其中,第四种情况可与第二种(或,第三种)情况合并
代码实现:
int minDepth(TreeNode* root) { | |
if (!root) return 0; | |
if (!root->left) return 1 + minDepth(root->right); // 左子树为空(包括左右子树均为空的情形) | |
if (!root->right) return 1 + minDepth(root->left); // 右子树为空 | |
return 1 + min(minDepth(root->right), minDepth(root->left)); // 左右子树均不为空 | |
} |
# 写法二
代码实现:
int minDepth(TreeNode* root) { // 返回 root 到叶节点的最小深度 | |
if (root == nullptr) return 0; | |
int left = minDepth(root->left); // 左子树最小深度 | |
int right = minDepth(root->right); // 右子树最小深度 | |
if (!left || !right) // 左子树为空,或,右子树为空,最小深度为 1 + left + right | |
return 1 + left + right; | |
return 1 + min(left, right); // 左子树与右子树非空,最小深度为 1 + min (left, right) | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:,其中, 为二叉树的最大深度(这里考虑了递归时栈空间的开销)
- 最坏情况下,树呈现链状,空间复杂度为
- 平均情况下,树的高度与节点数的对数正相关,空间复杂度为
# Method 2: 层序遍历
算法思路:
- 逐层遍历,每层按从左到右顺序遍历
- 若遇到叶节点(即,左右子节点均为空),则返回当前遍历到的层数
代码实现:
int minDepth(TreeNode* root) { | |
int ans = 0; | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
ans++; | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
TreeNode* tmp = que.front(); | |
que.pop(); | |
if (tmp->left == nullptr && tmp->right == nullptr) return ans; //tmp 为叶节点 | |
if (tmp->left) que.push(tmp->left); | |
if (tmp->right) que.push(tmp->right); | |
} | |
} | |
return ans; | |
} |
时间复杂度:,其中, 为二叉树的节点数
空间复杂度:
# LeetCode 112. 路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
输入:root = [1,2,3], targetSum = 5
输出:false
解释:不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
提示:
- 树中节点的数目在范围 内
-
Node.val -
targetSum
# Method 1: 递归
hasPathSum 函数的功能:判断是否存在从当前节点 root 到叶节点的路径,使得路径和为 targetSum
假定从根节点到当前节点的路径和为 val ,则问题可以转换为:判断是否存在一条从当前节点的子节点到叶节点的路径,满足其路径和为 targetSum - val
因此,可以利用递归来实现这一系列问题的求解
算法思路:
-
确定递归的参数和返回值:
- 参数:根节点
root,期望的root-to-leaf路径和sum - 返回值:
bool类型,表示是否找到可行路径(设定返回值是为了在遇到可行路径时就返回,不再继续递归)
- 参数:根节点
-
递归终止条件:遇到叶节点,当前递归结束
-
单层递归的逻辑:
- 若
root是叶节点,判断当前路径是否满足条件 - 若不是叶节点,分别递归到左、右子树(注意,传入的第二个参数为
sum - root->val)
- 若
代码实现:
bool hasPathSum(TreeNode* root, int sum) { | |
if (!root) return false; // 空节点,递归返回 | |
if (!root->left && !root->right) | |
return root->val == sum; // 若当前叶节点的值等于 sum,路径符合条件,返回 true | |
return hasPathSum(root->left, sum - root->val) || | |
hasPathSum(root->right, sum - root->val); // 判断是否存在从子节点到叶节点路径和为 sum - root->val 的路径 | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,这里考虑了递归使用的栈空间
本题也可以累加路径和,在遇到叶节点时,判断路径和是否与目标值相等,但那样比较麻烦,例如:LeetCode 提交记录
参考:
# LeetCode 113. 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
示例 2:

输入:root = [1,2,3], targetSum = 5
输出:[]
示例 3:
输入:root = [1,2], targetSum = 0
输出:[]
提示:
- 树中节点总数在范围 内
-
Node.val -
targetSum
# Method 1: 递归
算法思路:综合 LeetCode 257. 二叉树的所有路径 和 LeetCode 112. 路径总和 这两题的思想
递归函数的参数:
TreeNode *root:当前节点vector<int> path:记录从二叉树根节点到当前节点的路径(注意,参数传递方式为值传递)int sum:从当前节点到叶节点应满足的路径和(注意,参数传递方式为值传递)
为避免 getPaths 函数需要传入太多参数,特将 vector<vector<int>> ans 设置为全局变量(记录所有可行路径)
代码实现:
vector<vector<int>> ans; | |
void getPaths(TreeNode *root, vector<int> path, int sum) { | |
if (!root) return; // 空节点,递归终止 | |
path.push_back(root->val); // 更新路径 | |
if (!root->left && !root->right) { //root 为叶节点 | |
if (root->val == sum) // 若当前值等于 sum ,路径符合要求,将其添加到 ans | |
ans.push_back(path); | |
return; | |
} | |
getPaths(root->left, path, sum - root->val); // 递归到左子树(传入 sum - root->val) | |
getPaths(root->right, path, sum - root->val); // 递归到右子树(传入 sum - root->val) | |
} | |
vector<vector<int>> pathSum(TreeNode* root, int targetSum) { | |
vector<int> path; | |
getPaths(root, path, targetSum); | |
return ans; | |
} |
时间复杂度:,其中 是二叉树的节点数
- 在最坏情况下,树的上半部分为链状,下半部分为完全二叉树,并且从根节点到每一个叶节点的路径都符合要求
- 此时,路径数目为 ,每一条路径的节点个数也为 ,因此总的时间复杂度为
空间复杂度:,栈空间的开销
# LeetCode 114. 二叉树展开为链表
114. Flatten Binary Tree to Linked List
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:

输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [0]
输出:[0]
提示:
- The number of nodes in the tree is in the range [0, 2000].
- -100 <= Node.val <= 100
进阶:Can you flatten the tree with O(1) extra space?
# Method 1: 暴力法
算法思路:
首先按照前序遍历顺序将二叉树节点依次存入队列中
队首到队尾的元素对应于所需构建的二叉树链表的首端和尾端(因为展开后的单链表与二叉树前序遍历顺序相同)
于是,依据队列中的元素重构二叉树即可:对于队列中的任意元素(记作 node ),其 left 指针应为空指针,right 指针应指向其在队列中的下一个元素
queue<TreeNode*> que; // 存放先序遍历结果 | |
void traverse(TreeNode* root) { // 先序遍历 | |
que.push(root); | |
if (root->left) traverse(root->left); | |
if (root->right) traverse(root->right); | |
} | |
void flatten(TreeNode* root) { | |
if (root == nullptr)return; // 二叉树为空 | |
traverse(root); // 获取先序遍历序列 | |
root = que.front(); | |
que.pop(); | |
while (!que.empty()) { // 构造链表 | |
root->left = nullptr; // 注意这里需要将 left 指针置为空指针 | |
root->right = que.front(); | |
que.pop(); | |
root = root->right; | |
} | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,考虑了存放二叉树前序遍历结果所需空间,不考虑递归所需栈空间
# Method 2: 递归
算法思路:
定义一个递归函数,用于将以 root 为根节点的二叉树展开成链表
单层递归的具体逻辑为:
- 将左子树展开成链表(为便于表述,记作 左子树链表)
- 将右子树展开成链表(为便于表述,记作 右子树链表)
- 拼接左子树链表与右子树链表
- 将拼接结果作为新的右子树,并将左子树置为空
其中,题目要求展开所得的单链表与二叉树前序遍历顺序相同(即,根 - 左 - 右),因此,需要将右子树链表拼接在左子树链表的后面。即,需要找到左子树链表的尾端,令其 right 指针指向右子树链表的首端
代码实现:
void flatten(TreeNode* root) { | |
if (root == nullptr) return; | |
flatten(root->left); // 将左子树展开成链表 | |
flatten(root->right); // 将右子树展开成链表 | |
TreeNode* tmp = root->right; // 备份右子树的根节点 | |
root->right = root->left; // 将 root 的左子树修改为 root 的右子树 | |
root->left = nullptr; //root 的左子节点置为空指针 | |
TreeNode* node = root; //root 左子树与 root 右子树的拼接点(即,左子树链表的尾端) | |
while (node->right != nullptr) { | |
node = node->right; | |
} | |
node->right = tmp; // 将 root 右子树链表拼接在 root 左子树链表上 | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,不考虑递归所需栈空间
# LeetCode 116. 填充每个节点的下一个右侧节点指针
LeetCode 116. Populating Next Right Pointers in Each Node
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node* next;
Node() : val(0), left(NULL), right(NULL), next(NULL) {}
Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}
Node(int _val, Node* _left, Node* _right, Node* _next)
: val(_val), left(_left), right(_right), next(_next) {}
};
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。
初始状态下,所有 next 指针都被设置为 NULL 。
示例 1:

输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
示例 2:
输入:root = []
输出:[]
提示:
- 树中节点的数量在范围 内
-
Node.val
进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
# Method 1: 层序遍历
类似于 LeetCode 102. 二叉树的层序遍历
算法思路:
- 逐层遍历、每层按从左到右顺序遍历,利用队列存放待访问的节点
- 在遍历过程中,将 节点的
next指针 指向 同一层的后一个节点(即,指向 队列的下一个元素)
代码实现:
Node* connect(Node* root) { | |
queue<Node*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
Node* cur = que.front(); | |
que.pop(); | |
if (i < size - 1) cur->next = que.front(); // 除最右侧节点外,每个节点的 next 指针均指向右侧节点 | |
if (cur->left) que.push(cur->left); | |
if (cur->right) que.push(cur->right); | |
} | |
} | |
return root; | |
} |
时间复杂度:,其中 是节点个数
空间复杂度:
# Method 2: 使用已建立的 next 指针
算法思路:
本题的二叉树为满二叉树,每一层的节点都是满的。针对满二叉树而言, next 指针的连接方式有两种类型:
-
所连接的两个节点具有共同的父节点
![Connection 1]()
-
所连接的两个节点具有不同的父节点,但他们的父节点通过
next指针连接![Connection 2]()


算法流程:
-
定义
pre指向根节点,即,令pre = root -
遍历二叉树的每一层,即,执行以下循环,循环条件是
pre->left不为空:- 定义
cur指向pre所在层的节点,初始时指向pre - 遍历
cur,建立cur下一层节点的next指针:- 若
cur的左子节点不为空,则右子节点必不为空,通过cur->left->next = cur->right连接cur的两个子节点 - 若
cur的左子节点不为空 且cur的next指针不为空,通过cur->right->next = cur->next->left连接cur的右子节点与cur->next的左子节点 cur向右移动,即,更新cur = cur->next
- 若
- 完成当前层的连接后,进入下一层重复操作,即
pre向下移动(更新pre = pre->left)
- 定义
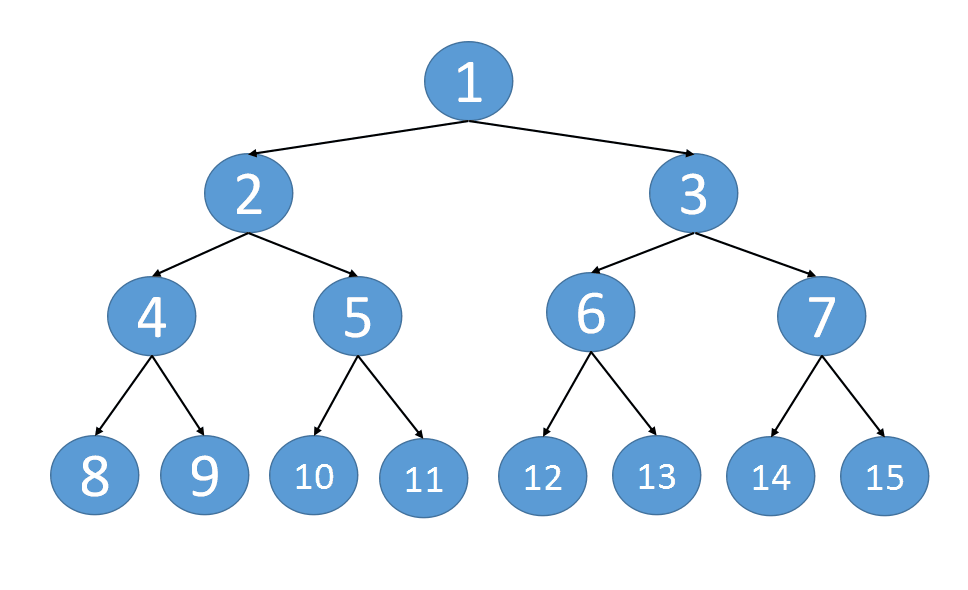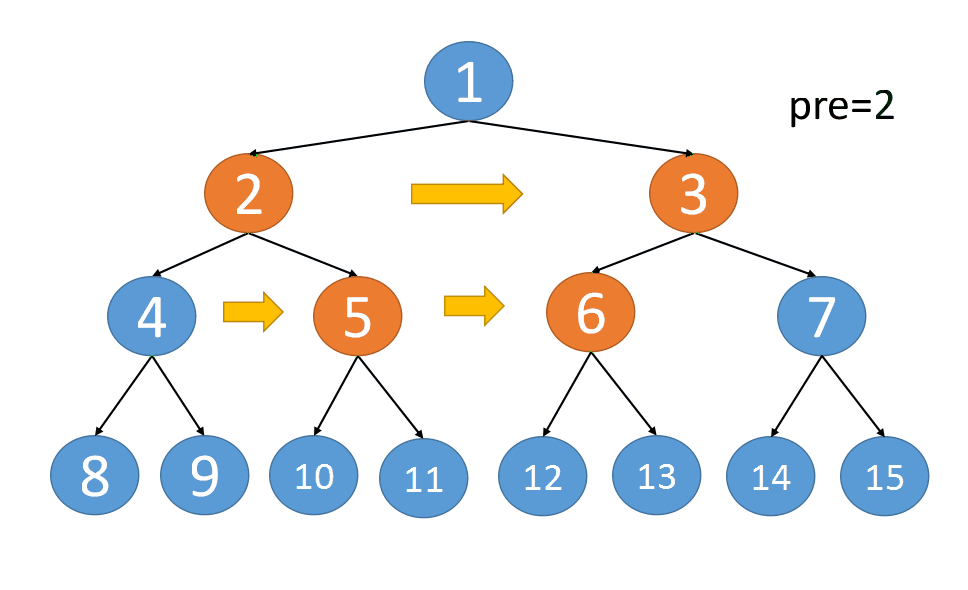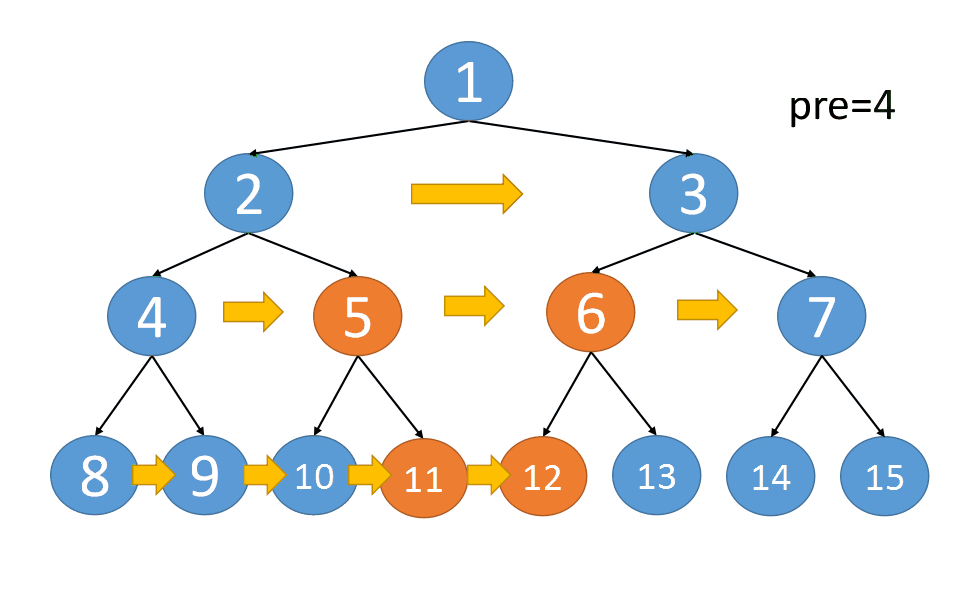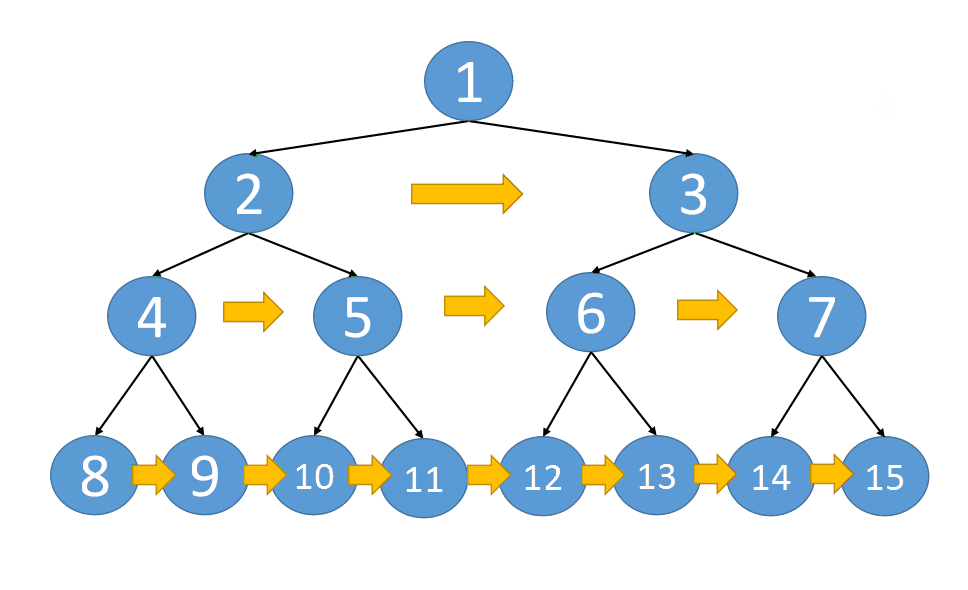
需要注意:
pre表示的是pre所在层的最左侧节点- 遍历
cur时,cur所在层节点的next指针均已建立完成,此时建立的是下一层节点的next指针
代码实现:
Node* connect(Node* root) { | |
if (root == nullptr) return root; | |
Node* pre = root; | |
while (pre->left != nullptr) { // 遍历二叉树的每一层 | |
Node* cur = pre; | |
while (cur != nullptr) { // 遍历 pre 所在层的节点,建立下一层节点的 next 指针 | |
// 注意,外层的 while 循环已确保 cur 的下一层不为空 | |
cur->left->next = cur->right; // 连接同一个父节点的两个子节点 | |
if (cur->next != nullptr) | |
cur->right->next = cur->next->left; // 连接不同父节点之间子节点 | |
cur = cur->next; // 向右移动 | |
} | |
pre = pre->left; // 向下一层移动 | |
} | |
return root; | |
} |
时间复杂度:,每个节点只访问一次
空间复杂度:,不需要额外空间用于存储
以上算法可改写成递归算法(即,深度优先搜索)
递归法的代码实现:
void DFS(Node* root) { // 更新 root 左右子节点的 next 指针 | |
if (root == nullptr || root->left == nullptr) return; | |
root->left->next = root->right; | |
if (root->next != nullptr) | |
root->right->next = root->next->left; | |
DFS(root->left); | |
DFS(root->right); | |
} | |
Node* connect(Node* root) { | |
DFS(root); | |
return root; | |
} |
参考:
# LeetCode 117. 填充每个节点的下一个右侧节点指针 II
LeetCode 117. Populating Next Right Pointers in Each Node II
给定一个二叉树:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。
初始状态下,所有 next 指针都被设置为 NULL 。
示例 1:

输入:root = [1,2,3,4,5,null,7]
输出:[1,#,2,3,#,4,5,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。
示例 2:
输入:root = []
输出:[]
提示:
- 树中的节点数在范围 内
-
Node.val
进阶:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序的隐式栈空间不计入额外空间复杂度。
# 思路
与 LeetCode 116. 填充每个节点的下一个右侧节点指针 不同,本题并未限定二叉树为满二叉树
因此,针对每个节点,都需在其右侧寻找距离其最近的节点
# Method 1: 层序遍历
算法思路:与 LeetCode 116. 填充每个节点的下一个右侧节点指针 的 Method 1 相同,利用队列存放待访问的节点,在二叉树每一层的访问完成之前,队列下一个元素即为当前元素 next 指针应指向的对象
该算法与 二叉树是否为满二叉树 无关
代码实现:
Node* connect(Node* root) { | |
queue<Node*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
Node* cur = que.front(); | |
que.pop(); | |
if (i < size - 1) cur->next = que.front(); | |
if (cur->left) que.push(cur->left); | |
if (cur->right) que.push(cur->right); | |
} | |
} | |
return root; | |
} |
时间复杂度:,其中 是节点个数
空间复杂度:
# Method 2: 使用已建立的 next 指针
算法思路:
-
与 LeetCode 116. 填充每个节点的下一个右侧节点指针 的 Method 2 类似,可以利用已经建立了的
next指针:即,在遍历cur的过程中,与cur处于同一层的各个节点的next指针均已建立完成,需要建立的是cur下一层节点的next指针 -
不同的是,由于二叉树不一定为满二叉树,
cur不一定存在左、右子节点,如果存在的话,cur->left、cur->right应分别指向cur->left右侧的第一个节点、cur->right右侧的第一个节点,如 示例 1 所示 -
由于
pre不一定具有左子节点,在更新pre时,不能简单地令pre = pre->left,需要对pre下一层的节点情况进行判断,更准确地说,需要找到pre下一层的最左侧节点,将其作为新的pre
因此,本题在 LeetCode 116. 填充每个节点的下一个右侧节点指针 的基础上,作出以下改变:
-
定义
leftmost指向pre下一层的最左侧节点 -
定义一个
handle函数,在root右侧找到第一个非叶节点,返回其左子节点(不存在左子节点时,则返回右子节点)- 该函数用于确定
cur->left(不存在cur->right时)、cur->right的next指针的方向,也用于leftmost的更新
- 该函数用于确定
代码实现:
Node* handle(Node* root) { // 寻找 root 右侧第一个非叶节点的子节点(靠左侧的子节点) | |
Node* cur = root->next; | |
while (cur != nullptr) { | |
if (cur->left) return cur->left; | |
if (cur->right) return cur->right; | |
cur = cur->next; | |
} | |
return nullptr; | |
} | |
Node* connect(Node* root) { | |
if (root == nullptr) return root; | |
Node* pre = root; | |
Node* leftmost = pre->left ? pre->left : pre->right; //pre 下一层的最左侧节点 | |
while (leftmost != nullptr) { // 当 pre 不是叶节点时执行循环 | |
Node* cur = pre; | |
while (cur != nullptr) { | |
if (cur->left) // 当 cur 存在左子节点时,其 next 指针指向 cur->left 右侧第一个节点 | |
cur->left->next = cur->right ? cur->right : handle(cur); | |
if (cur->right) // 当 cur 存在右子节点时,其 next 指针指向 cur->right 右侧第一个节点 | |
cur->right->next = handle(cur); | |
cur = cur->next; //cur 向右移动 | |
} | |
pre = leftmost; //pre 向下移动:更新 pre 为 leftmost | |
if (pre->left) // 更新 leftmost | |
leftmost = pre->left; | |
else if (pre->right) | |
leftmost = pre->right; | |
else | |
leftmost = handle(pre); | |
} | |
return root; | |
} |
时间复杂度:,其中 是节点个数,每个节点至多被访问 3 次
- 确定
cur->left和cur->right的next指针时,至多访问cur右侧各个节点 1 次 - 遍历
cur时,访问各节点 1 次 - 更新
leftmost时,至多访问pre下一层的各个节点 1 次
空间复杂度:
注意,本题的样例并不一定为满二叉树,不能将该算法改写成递归法(深度优先搜索)。因为在调用
handle时,与root同一层节点的next指针可能并未更新完成,这将导致handle函数返回错误结果
与 Method 1 相比,Method 2 的时间复杂度相对较高,空间复杂度相对较低
# Method 3: 链表
可以将二叉树的每一层都看成一个链表
算法流程:
-
定义:指针
dummyHead指向虚拟头节点,指针cur指向当前遍历到的二叉树节点,指针LinkedNode指向链表的当前节点 -
当
cur不为空时,执行循环:- 令
LinkedNode = dummyHead - 在同一层上遍历
cur:- 若
cur的左子节点不为空,将左子节点串进链表,并更新LinkedNode - 若
cur的右子节点不为空,将右子节点串进链表,并更新LinkedNode - 继续访问这一层的下一个节点
- 若
- 更新
cur为下一层的最左侧节点,即,cur = dummyHead->next - 重置哑结点
dummyHead的next指针,即,dummyHead->next = nullptr
- 令
在内层的循环中,遍历的是
cur所在层的节点,串联的是cur下一层的节点
代码实现:
Node* connect(Node* root) { | |
if (root == nullptr) return root; | |
Node* cur = root; // 当前节点 | |
Node* dummyHead = new Node(); // 链表的哑结点(定义在最外层,确保空间复杂度为 O (1)) | |
Node* LinkedNode = nullptr; // 链表的当前节点 | |
while (cur != nullptr) { | |
LinkedNode = dummyHead; | |
while (cur != nullptr) { // 遍历 cur ,将 cur 下一层的节点串联成链表 | |
if (cur->left) { | |
LinkedNode->next = cur->left; // 将 cur 左子节点串进链表 | |
LinkedNode = LinkedNode->next; // LinkedNode 右移 | |
} | |
if (cur->right) { | |
LinkedNode->next = cur->right; // 将 cur 右子节点串进链表 | |
LinkedNode = LinkedNode->next; // LinkedNode 右移 | |
} | |
cur = cur->next; //cur 向右移动 | |
} | |
cur = dummyHead->next; //cur 向下移动 | |
dummyHead->next = nullptr; // 重置 dummyHead 的 next 指针 | |
} | |
return root; | |
} |
时间复杂度:
空间复杂度:
# LeetCode 124. 二叉树中的最大路径和
# 二叉树的最大路径和
124. Binary Tree Maximum Path Sum
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:

输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:

输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
提示:
- 树中节点数目范围是
-
Node.val
# Method: 递归
算法思路:
定义一个递归函数 int maxGain(TreeNode* root) ,用于计算 root 节点的最大贡献值,即:在以 root 为根节点的二叉树中,计算以 root 为起点的路径的最大和
定义一个全局变量 maxSum ,用于存储二叉树的最大路径和
递归终止条件:遇到空节点,当前递归结束
单层递归的逻辑:
- 递归到左子节点,在左子树中计算以左子节点为起点的最大路径和,记作 leftGain ,即 leftGain = maxGain (root->left)
- 递归到右子节点,在右子树中计算以右子节点为起点的最大路径和,记作 rightGain ,即 rightGain = maxGain (root->right)
- 在以 root 为根节点的二叉树中,包含 root 节点的路径的最大和为:sum = root->val + max (leftGain, 0) + max (rightGain, 0)
- 这里实际计算的是 “左子树 - root - 右子树” 路径的最大和
- 当左子节点和右子节点的贡献值为负数时,不能将左子节点和右子节点计入 root 节点所对应的、具有最大和的路径(因为加上一个负数会使得和变小),所以,我们累加的是 max (leftGain, 0) 和 max (rightGain, 0)
- 在以 root 为根节点的二叉树中,以 root 为起点的路径的最大和为:gain = max (root->val + max (leftGain, 0), root->val + max (rightGain, 0))
- root->val + max (leftGain, 0) 为 root 节点到左子树的最大路径和
- root->val + max (rightGain, 0) 为 root 节点到右子树的最大路径和
- 更新二叉树的最大路径和:maxSum = max (maxSum, sum)
- 注意,sum 始终大于或等于 gain ,因此,这里需根据 sum 来更新 maxSum (可结合 示例 1 和 示例 2 进行理解)
- 返回 root 节点的贡献值 gain
代码实现:
int maxSum = INT_MIN; // 二叉树的最大路径和 | |
int maxPathSum(TreeNode* root) { | |
maxGain(root); | |
return maxSum; | |
} | |
int maxGain(TreeNode* root) { | |
if (root == nullptr) return 0; | |
int leftGain = max(maxGain(root->left), 0); | |
int rightGain = max(maxGain(root->right), 0); | |
maxSum = max(maxSum, root->val + leftGain + rightGain); | |
return root->val + max(leftGain, rightGain); | |
} |
时间复杂度:,其中 是二叉树的节点个数
空间复杂度:
# 三叉树中的最大路径和
华为 2022.10.12 第二道笔试题
#include <iostream> | |
#include <vector> | |
#include <queue> | |
#include <climits> | |
#include <algorithm> | |
using namespace std; | |
struct TreeNode { | |
int val; | |
TreeNode* left; | |
TreeNode* mid; | |
TreeNode* right; | |
TreeNode (int _val) : val(_val), left(nullptr), mid(nullptr), right(nullptr) {} | |
// TreeNode () : val(0), left(nullptr), mid(nullptr), right(nullptr) {} | |
// TreeNode (int _val, TreeNode* _left, TreeNode* _mid, TreeNode* _right) : val(_val), left(_left), mid(_mid), right(_right) {} | |
}; | |
TreeNode* buildTree(vector<int>& nums) { // 利用层序遍历数组 nums 构建三叉树 | |
TreeNode* root = new TreeNode(nums[0]); | |
queue<TreeNode*> que; | |
que.push(root); | |
int idx = 1; | |
while (!que.empty() && idx < nums.size()) { | |
int size = que.size(); | |
for (int i = 0; i < size; ++i) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
if (idx < nums.size() && nums[idx] != -1) { //left 子节点 | |
node->left = new TreeNode(nums[idx]); | |
que.push(node->left); | |
// cout << node->left->val << endl; | |
} | |
else node->left = nullptr; | |
++idx; | |
if (idx < nums.size() && nums[idx] != -1) { //mid 子节点 | |
node->mid = new TreeNode(nums[idx]); | |
que.push(node->mid); | |
// cout << node->mid->val << endl; | |
} | |
else node->mid = nullptr; | |
++idx; | |
if (idx < nums.size() && nums[idx] != -1) { //right 子节点 | |
node->right = new TreeNode(nums[idx]); | |
que.push(node->right); | |
// cout << node->right->val << endl; | |
} | |
else node->right = nullptr; | |
++idx; | |
} | |
} | |
return root; | |
} | |
vector<int> order; | |
void traversal(TreeNode* root) { // 层序遍历三叉树 | |
if (root == nullptr) return; | |
queue<TreeNode*> que; | |
que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
for (int i = 0; i < size; ++i) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
order.push_back(node->val); | |
if (node->left) que.push(node->left); | |
if (node->mid) que.push(node->mid); | |
if (node->right) que.push(node->right); | |
} | |
} | |
} | |
int ans = INT_MIN; // 最大路径和 | |
int gain(TreeNode* root) { // 计算 以 root 为起点、向下延申的最大路径和 | |
if (root == nullptr) return 0; | |
int left = gain(root->left); //left 子树最大路径和 | |
left = max(left, 0); | |
int mid = gain(root->mid); //mid 子树最大路径和 | |
mid = max(mid, 0); | |
int right = gain(root->right); //right 子树最大路径和 | |
right = max(right, 0); | |
int maxgain = root->val + max({left + mid, left + right, mid + right}); // 找出三条路径中的最大路径和:从 left 经 root 到 mid 、从 left 经 root 到 right 、从 mid 经 root 到 right | |
ans = max(ans, maxgain); // 更新最大路径和 | |
return root->val + max({left, mid, right}); // 以 root 为起点、向下延申的最大路径和 | |
} | |
int main() { | |
// 读取输入 | |
int n = 0; | |
cin >> n; | |
vector<int> nums(n, 0); // 三叉树的层序遍历数组(其中,-1 表示空节点) | |
for (int i = 0; i < n; ++i) cin >> nums[i]; | |
// int n = 19; | |
// vector<int> nums = {20, 12, 30, 15, -1, -1, -1, -1, -1, -1, 15, 5, 25, -1, -1, -1, 16, -1, 22}; | |
// 构建三叉树 | |
TreeNode* root = buildTree(nums); | |
//// 遍历三叉树,检查三叉树构建是否正确 | |
// traversal(root); | |
// for (int i = 0; i < order.size(); ++i) cout << order[i] << " "; | |
// cout << endl; | |
// 计算最大路径和 | |
gain(root); | |
cout << ans << endl; | |
return 0; | |
} |
# LeetCode 144. 二叉树的前序遍历
LeetCode 144. Binary Tree Preorder Traversal
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:

输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:

输入:root = [1,2]
输出:[1,2]
示例 3:

输入:root = [1,null,2]
输出:[1,2]
提示:
- 树中节点数目在范围 内
-
Node.val
进阶:递归算法很简单,你可以通过迭代算法完成吗?
# 思路
按照访问根节点 —— 左子树 —— 右子树的方式遍历这棵树,左子树或者右子树按照同样的方式遍历
注意二叉树节点的定义:
struct TreeNode { | |
int val; | |
TreeNode *left; | |
TreeNode *right; | |
TreeNode() : val(0), left(nullptr), right(nullptr) {} | |
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} | |
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} | |
}; |
# Method 1: 递归
算法流程:
定义递归函数 preorder(root, res) ,将遍历到的 root 节点的结果添加到目标数组 res :
- 按照定义,首先将
root节点的值加入数组 - 递归调用
preorder(root.left)来遍历root节点的左子树 - 递归调用
preorder(root.right)来遍历root节点的右子树
递归终止的条件为碰到空节点
代码实现:
vector<int> preorderTraversal(TreeNode* root) { | |
vector<int> res; | |
preorder(root,res); // 前序遍历,调用递归函数 | |
return res; | |
} | |
void preorder(TreeNode* root, vector<int> &res) { | |
if (root == nullptr) return; | |
res.push_back(root->val); // 当前节点 | |
preorder(root->left, res); // 左子树 | |
preorder(root->right, res); // 右子树 | |
} |
时间复杂度:,其中 是二叉树的节点数,每一个节点恰好被遍历一次
空间复杂度:,为递归过程中栈的开销,这里忽略了目标数组所需空间
- 平均情况下,栈所需空间为
- 最坏情况下树呈现链状,空间复杂度为
# Method 2: 迭代
递归的实现:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,递归返回时再从栈顶弹出上一次递归的各项参数,故而递归可以返回到上一层
不同于递归法,迭代法 显式地 维护一个栈,以实现遍历
由于栈的后进先出特性,要想先访问左子树、后访问右子树,需要先将右子树入栈、后将左子树入栈
算法思路:
-
设计一个栈,用于存放将访问的树的根节点(只放入非空节点)
-
将根节点入栈,然后重复以下过程,直到栈为空
- 从栈中取出一个节点,记录节点的值
- 将右子节点放入栈
- 将左子节点放入栈
代码实现:
vector<int> preorderTraversal(TreeNode* root) { | |
vector<int> res; | |
if(root == nullptr) return res; | |
stack<TreeNode*> stk; // 栈存放二叉树节点的指针 | |
stk.push(root); // 根节点入栈 | |
while (!stk.empty()) { // 栈不为空,节点未遍历完 | |
TreeNode* cur = stk.top(); // 栈顶元素(根节点) | |
stk.pop(); // 出栈 | |
res.push_back(cur->val); // 将节点的值加入到目标数组 | |
if(cur->right) stk.push(cur->right); // 将右子节点压入栈 | |
if(cur->left) stk.push(cur->left); // 将左子节点压入栈 | |
} | |
return res; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,栈的开销,这里忽略了目标数组所需空间
事实上,迭代法也可以如下实现:
vector<int> preorderTraversal(TreeNode* root) { | |
vector<int> ans; | |
stack<TreeNode*> st; | |
TreeNode* node = root; | |
while (!st.empty() || node != nullptr) { | |
while (node != nullptr) { // 遍历 node ,直到到达最底部 | |
ans.push_back(node->val); // 将 node 的值添加到目标数组 | |
st.push(node); // 之后还需访问 node 右子节点,故而将 node 放入栈 | |
node = node->left; // 更新 node 为左子节点,继续遍历 | |
} | |
node = st.top(); // 循环结束时,栈顶指向最底层节点 | |
st.pop(); | |
node = node->right; // 遍历右子节点 | |
} | |
return ans; | |
} |
# LeetCode 145. 二叉树的后序遍历
LeetCode 145. Binary Tree Postorder Traversal
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:

输入:root = [1,null,2,3]
输出:[3,2,1]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点数目在范围 内
-
Node.val
进阶:递归算法很简单,你可以通过迭代算法完成吗?
# 思路
按照左子树 —— 右子树 —— 根节点的顺序,对二叉树的每个节点进行遍历
# Method 1: 递归
代码实现:
vector<int> postorderTraversal(TreeNode* root) { | |
vector<int> res; | |
postorder(root, res); // 中序遍历 | |
return res; | |
} | |
void postorder(TreeNode* root, vector<int> &res) { | |
if (root == nullptr) return; | |
postorder(root->left, res); // 左子树 | |
postorder(root->right, res); // 右子树 | |
res.push_back(root->val); // 根节点 | |
} |
时间复杂度:,其中, 为二叉树的节点个数
空间复杂度:
# Method 2: 迭代
# 方案一
算法流程:
-
按照 “根 - 右 - 左” 的顺序访问节点,并依次将节点值添加到目标数组(类似于 144. 二叉树的前序遍历 ,仅仅是访问 左子节点 和 右子节点 的先后顺序不同而已)
-
将目标数组反转,即可得按 “左 - 右 - 根” 顺序访问的结果
代码实现:
vector<int> postorderTraversal(TreeNode* root) { | |
vector<int> res; | |
if (root == nullptr) return res; | |
stack<TreeNode*> stk; | |
stk.push(root); | |
while (!stk.empty()) { // 按照 根 - 右 - 左 的顺序遍历 | |
TreeNode* cur = stk.top(); | |
stk.pop(); | |
res.push_back(cur->val); // 访问根节点,并将其出栈 | |
if (cur->left) stk.push(cur->left); // 左子节点先入栈,后访问 | |
if (cur->right) stk.push(cur->right); // 右子节点后入栈,先访问 | |
} | |
reverse(res.begin(), res.end()); // 将数组反转,可得 左 - 右 - 根 遍历顺序的结果 | |
return res; | |
} |
# 方案二
可以采取类似 LeetCode 94. 二叉树的中序遍历 的迭代法
不过,这里有些许不同:
- 对于中序遍历,从栈中弹出节点时,其左子树已访问完,可以直接访问该节点,然后访问右子树
- 对于后序遍历,从栈中弹出节点时,只能确定其左子树已访问完,无法确定右子树是否被访问过
于是,引入一个指针 prev 来记录子树的访问情况:
- 当一个节点及其左右子树均已访问过,令
prev指向该节点 - 回溯到父节点后,可以根据其右子节点指针是否等于
prev,来判断右子节点是否被访问过
代码实现:
vector<int> postorderTraversal(TreeNode *root) { | |
vector<int> res; | |
stack<TreeNode*> stk; | |
TreeNode *node = root; // 当前遍历节点 | |
TreeNode *prev = nullptr; // 已访问过的子节点 | |
while (!stk.empty() || node != nullptr) { // 节点未遍历完 | |
while (node != nullptr) { // 遍历至 node 左子树的最底部 | |
stk.push(node); | |
node = node->left; | |
} | |
node = stk.top(); // 左子树最底部的节点 | |
stk.pop(); | |
if (node->right == nullptr || node->right == prev) { // 右子树为空 或 右子树已访问过 | |
res.push_back(node->val); // 将当前节点的值添加到目标数组 | |
prev = node; // 用 prev 标记当前节点及其子节点已访问 | |
node = nullptr; // 左子树已访问过,下次循环无需再次访问 | |
} else { // 未访问过右子树 | |
stk.push(node); //node 重新入栈,待右子树访问结束后才访问 node | |
node = node->right; // 访问 node 的右子树 | |
} | |
} | |
return res; | |
} |
时间复杂度:,其中, 为二叉树的节点个数
空间复杂度:
针对前、中、后序三种遍历方式,也可以采用 代码随想录:二叉树的统一迭代法 思路:
- 对于 已经遍历过、但并未把其值添加到目标数组 的节点(根节点),将其放入栈,并紧接着放入一个空指针作为标记;对于未曾遍历过的节点(左右子节点),直接放入栈,无需添加空指针标记
- 于是,在后续操作过程中,若栈顶为空指针,将其弹出后,所得的新栈顶元素则为 已经遍历过、但未把值添加到目标数组的节点
# LeetCode 199. 二叉树的右视图
LeetCode 199. Binary Tree Right Side View
给定一个二叉树的根节点 root ,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:

输入:root = [1,2,3,null,5,null,4]
输出:[1,3,4]
示例 2:
输入:root = [1,null,3]
输出:[1,3]
示例 3:
输入:root = []
输出:[]
提示:
- 二叉树的节点个数的范围是
-
Node.val
# 思路
逐层、从左到右遍历,利用队列存放待访问的节点
在遍历过程中,只需将 每层最右侧节点的值 添加到目标数组
# Method: 广度优先搜索
算法流程:与 LeetCode 102. 二叉树的层序遍历 类似,区别在于,只需记录每一层最右侧节点的值
代码实现:
vector<int> rightSideView(TreeNode* root) { | |
vector<int> res; | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
TreeNode* node = nullptr; // 当前遍历节点的指针 | |
for (int i = 0; i < size; i++) { //for 循环结束时,node 指向该层最右侧节点 | |
node = que.front(); | |
que.pop(); | |
if (node->left) que.push(node->left); | |
if (node->right) que.push(node->right); | |
} | |
res.push_back(node->val); // 仅记录每一层最右侧节点的值 | |
} | |
return res; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# Method: 深度优先搜索
可参考 力扣官方题解:二叉树的右视图 的方法一
# LeetCode 222. 完全二叉树的节点个数
LeetCode 222. Count Complete Tree Nodes
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例 1:

输入:root = [1,2,3,4,5,6]
输出:6
示例 2:
输入:root = []
输出:0
示例 3:
输入:root = [1]
输出:1
提示:
- 树中节点的数目范围是 .
-
Node.val - 题目数据保证输入的树是 完全二叉树
进阶: 遍历树来统计节点是一种时间复杂度为 的简单解决方案。你可以设计一个更快的算法吗?
# Method 1: 遍历
算法思路:遍历二叉树的所有节点,逐个计数
代码实现:
int countNodes(TreeNode* root) { | |
if (!root) return 0; | |
int left = countNodes(root->left); // 左子树节点数 | |
int right = countNodes(root->right); // 右子树节点数 | |
return 1 + left + right; | |
} |
时间复杂度:,其中 为节点数
空间复杂度:,未考虑递归调用栈
这里采用的是递归法实现遍历(后序遍历),也可以采用迭代法实现
# Method 2: 寻找满二叉树
完全二叉树有两种情况:
- 最底层的叶节点是满的,即,二叉树为满二叉树。此时,二叉树的节点数为 ,其中, 是树的深度
- 最底层的叶节点没有满。此时,从根节点开始,分别递归左子树、右子树,递归到一定深度时就会出现满二叉树,然后按照第一种情况计算节点数量即可

注意:若根节点的最左侧深度等于最右侧深度,则该二叉树为满二叉树
代码实现:
int countNodes(TreeNode* root) { | |
if (!root) return 0; | |
int leftDepth = 1, rightDepth = 1; | |
TreeNode* leftNode = root->left; | |
TreeNode* rightNode = root->right; | |
while (leftNode) { // 左子树的深度(最左侧的深度) | |
leftDepth++; | |
leftNode = leftNode->left; | |
} | |
while (rightNode) { // 右子树的深度(最右侧的深度) | |
rightDepth++; | |
rightNode = rightNode->right; | |
} | |
if (leftDepth == rightDepth) // 以 root 为根节点的二叉树为满二叉树 | |
return (1 << leftDepth) - 1; // 利用位左移计算 2^leftDepth | |
int leftCount = countNodes(root->left); // 递归左子树 | |
int rightCount = countNodes(root->right); // 递归右子树 | |
return 1 + leftCount + rightCount; | |
} |
时间复杂度:,其中 为节点数
- 对于第 层的节点($ 1 \le i \le \log {n}$),需要计算左右子树的深度,时间复杂度为
- 总的时间复杂度为
空间复杂度:,不考虑递归调用栈
# Method 3: 二分查找 + 位运算
# LeetCode 226. 翻转二叉树
LeetCode 226. Invert Binary Tree
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:

输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
示例 2:

输入:root = [2,1,3]
输出:[2,3,1]
示例 3:
输入:root = []
输出:[]
提示:
- 树中节点数目范围在 内
-
Node.val
# 思路
翻转二叉树的本质是:交换每个节点的左右子节点
因此,本题需遍历二叉树,并翻转每个节点的左右子节点
本题采用前序、中序、后序、层序遍历都可以
若采用中序遍历,即,按照 “翻转左子树、交换左右子节点、翻转右子树” 这一原理进行操作时,须注意,在交换左右子节点以后,原本的右子树将变成左子树,因此, “翻转右子树” 须通过 翻转左子树 实现。可参考 代码随想录:翻转二叉树
# Method 1: 前序遍历(递归)
代码实现:
TreeNode* invertTree(TreeNode* root) { | |
if (root == nullptr) return root; | |
swap(root->left, root->right); // 交换左、右子节点 | |
invertTree(root->right); // 将最初的左子树(新的右子树)翻转 | |
invertTree(root->left); // 将最初的右子树(新的左子树)翻转 | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# Method 2: 前序遍历(迭代)
# 写法一
类似于 144. 二叉树的前序遍历
代码实现:
TreeNode* invertTree(TreeNode* root) { | |
stack<TreeNode*> stk; | |
if (root) stk.push(root); | |
TreeNode* tmp = new TreeNode(); | |
while (!stk.empty()) { | |
tmp = stk.top(); | |
stk.pop(); | |
swap(tmp->left, tmp->right); // 交换左右子节点 | |
if (tmp->left) stk.push(tmp->left); // 将最初的右子节点(新的左子节点)入栈 | |
if (tmp->right) stk.push(tmp->right); // 将最初的左子节点(新的右子节点)入栈 | |
} | |
return root; | |
} |
# 写法二
类似于 二叉树深度优先搜索的统一迭代法 ,在第一次访问到某个节点时,不对该节点进行处理,反而将其重新放入栈,并紧接着放入一个空指针
代码实现:
TreeNode* invertTree(TreeNode* root) { | |
stack<TreeNode*> stk; | |
if (root) stk.push(root); | |
while (!stk.empty()) { | |
TreeNode* node = stk.top(); | |
stk.pop(); | |
if (node == NULL) { // 遇到空指针,意味着第二次访问到根节点 | |
node = stk.top(); | |
stk.pop(); | |
swap(node->left, node->right); // 将左右子节点进行交换 | |
} else { // 非空指针,意味着第一次访问到根节点 | |
if (node->right) stk.push(node->right); // 将右子节点入栈(此前并未交换过左右子节点) | |
if (node->left) stk.push(node->left); // 将左子节点入栈 | |
stk.push(node); // 访问过 node 节点,但并未处理,将其重新放入栈 | |
stk.push(NULL); // 加入空指针作为标记 | |
} | |
} | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# Method 3: 层序遍历
Method 1 与 Method 2 均为深度优先搜索,本题也还可以采用广度优先搜索,即,层序遍历
与 LeetCode 102. 二叉树的层序遍历 不同,本题无需按层输出结果,故而,在交换左右字节数时,不需要每次从队列中取出 个元素( 为当前所在层数),只需逐个取出元素即可
代码实现:
TreeNode* invertTree(TreeNode* root) { | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
TreeNode* tmp = new TreeNode(); | |
while (!que.empty()) { | |
tmp = que.front(); | |
que.pop(); | |
swap(tmp->left, tmp->right); // 交换左右子节点 | |
if (tmp->right) que.push(tmp->right); // 将最初的左子节点(新的右子节点)入队 | |
if (tmp->left) que.push(tmp->left); // 将最初的右子节点(新的左子节点)入队 | |
} | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# LeetCode 235. 二叉搜索树的最近公共祖先
235. Lowest Common Ancestor of a Binary Search Tree
给定一个二叉搜索树,找到该树中两个指定节点的 最近公共祖先 。
最近公共祖先 的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]

示例 1:
输入:root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出:6
解释:节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入:root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出:2
解释:节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [2,1], p = 2, q = 1
输出:2
提示:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
# 思路
本题可采用 LeetCode 236. 二叉树的最近公共祖先 中的方法求解
但由于本题的二叉树为二叉搜索树,可在 LeetCode 236. 二叉树的最近公共祖先 的基础上简化求解
# Method 1: 确定路径
算法思路:根据二叉搜索树的特性,分别找出从 root 到 p 的路径、从 root 到 q 的路径,然后从两个路径中找到最后一个公共节点,即为最近公共祖先
代码实现:
vector<TreeNode*> getPath(TreeNode *root, TreeNode * target) { // 记录从 root 到 target 的路径 | |
vector<TreeNode*> path; | |
while (root != target) { | |
path.push_back(root); | |
if (root->val > target->val) root = root->left; | |
else root = root->right; // 注意这里是 else 语句,与前面的 if 互斥 | |
} | |
path.push_back(root); | |
return path; | |
} | |
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { | |
vector<TreeNode*> pathP = getPath(root, p); // 获取 root 到 p 的路径 | |
vector<TreeNode*> pathQ = getPath(root, q); // 获取 root 到 q 的路径 | |
TreeNode *ans = NULL; // 公共祖先 | |
for (int i = 0; i < pathP.size() && i < pathQ.size(); i++) { // 找到深度最大的公共祖先 | |
if (pathP[i] == pathQ[i]) ans = pathP[i]; | |
else break; | |
} | |
return ans; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,这里考虑存放路径的数组空间
# Method 2: 迭代
算法思路:
-
如果当前节点的值大于
p和q的值,说明p和q在当前节点的左子树,因此,将当前节点移动到左子节点 -
如果当前节点的值小于
p和q的值,说明p和q在当前节点的右子树,因此,将当前节点移动到右子节点 -
如果当前节点值不满足以上两种情况,则当前节点就是
p和q的最近公共祖先
换而言之, p 和 q 的最近公共祖先节点的值一定落在 [p->val, q->val] 或者 [q->val, p->val] 区间内
代码实现:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { | |
while (true) { | |
if (root->val > p->val && root->val > q->val) { | |
root = root->left; | |
} else if (root->val < p->val && root->val < q->val) { | |
root = root->right; | |
} else { | |
break; | |
} | |
} | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
参考:力扣官方题解
# Method 3: 递归
算法思路:判断 root 的值是否落在 [p->val, q->val] 或者 [q->val, p->val] 区间内
代码实现:
TreeNode* helper(TreeNode *root, TreeNode* p, TreeNode* q) { | |
if (root->val < p->val && root->val < q->val) | |
return helper(root->right, p, q); | |
else if (root->val > p->val && root->val > q->val) | |
return helper(root->left, p, q); | |
else return root; | |
} | |
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { | |
return helper(root, p, q); | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,这里考虑了递归使用的栈空间
参考:代码随想录
# LeetCode 236. 二叉树的最近公共祖先
236. Lowest Common Ancestor of a Binary Tree
给定一个二叉树,找到该树中两个指定节点的最近公共祖先。
最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:

输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
提示:
- 树中节点数目在范围 内
-
Node.val - 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
# 思路
若 x 满足以下任意一种情况, x 是 p 和 q 的最近公共祖先
x的左子树包含p节点,并且x的右子树包含q节点(或者,x的左子树包含q节点 且x的右子树包含p节点)x恰好是p节点,并且x的其中一个子树包含q节点(或者,x恰好是q节点,并且x的其中一个子树包含p节点)
若按照后序遍历顺序来遍历二叉树(即,自底向上遍历二叉树),在所有满足条件的公共祖先中,一定是深度最大的祖先最先被访问到。因此,可以找到最近公共祖先
# Method 1
代码实现:
TreeNode *ans = nullptr; // 最近公共祖先 | |
bool helper(TreeNode *root, TreeNode *p, TreeNode *q) { // 判断以 root 为根节点的树是否含有 p 节点或 q 节点 | |
if (!root) return false; | |
bool left = helper(root->left, p, q); // 递归到左子树 | |
bool right = helper(root->right, p, q); // 递归到右子树 | |
if (left && right) ans = root; // 情形一 | |
if (root == p || root == q) { | |
if (left || right) // 情形二 | |
ans = root; | |
} | |
return (left || right) || (root == p || root == q); // 返回值:是否含有 p 节点或 q 节点 | |
} | |
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { | |
helper(root, p, q); | |
return ans; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,考虑了递归使用的栈空间
参考:力扣官方题解
# Method 2
算法思路:
针对情形二,在找到一个节点是 p 或者 q 的时候,直接返回当前节点即可,无需继续递归子树。在接下来的遍历中,如果找到了后继节点满足情形一,则修改返回值为后继节点,否则,继续返回已找到的节点即可
示意图:

代码实现:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { | |
if (root == p || root == q || root == NULL) return root; | |
TreeNode* left = lowestCommonAncestor(root->left, p, q); | |
TreeNode* right = lowestCommonAncestor(root->right, p ,q); | |
if (left && right) return root; // 左、右子树分别包含 p 、q 节点 | |
if (left || right) return left ? left : right; // 左子树或者右子树包含 p 或 q 节点 | |
return NULL; // 不包含 p 和 q 节点 | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,考虑了递归使用的栈空间
参考:代码随想录
本题也可以用哈希表存储所有节点的父节点,然后分别从
p、q节点开始向上访问父节点以及祖先节点,遇到的第一个公共祖先节点即为所求,具体可参考 力扣官方题解 - 方法二
# LeetCode 257. 二叉树的所有路径
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [1,2,3,null,5]
输出:["1->2->5","1->3"]
示例 2:
输入:root = [1]
输出:["1"]
提示:
- 树中节点的数目在范围 内
-
Node.val
# Method 1: 前序遍历
算法思路:
-
定义一个递归函数
getPaths,用于获取从root到叶节点的路径,具有以下输入参数:TreeNode* root:路径的起点string path:记录当前查找路径。注意,这里不能使用引用&:因为在探寻到叶节点后,需要回溯到它的父节点(以及祖先节点),回溯后的path不能包含已经遍历过的叶节点。因此,在每次调用时,都是采用复制赋值的方法传入path参数vector<string> &res:存放所有查找到的root-to-leaf路径
-
递归函数
getPaths的实现:- 若
root为空,当前的递归结束,否则,执行后续操作 - 将
root的值(需转换成string类型)添加到path中,以记录路径 - 若
root是叶节点,记录到的路径path即为一条从根节点到叶节点的路径,将path添加到答案数组res,当前递归结束 - 若
root不是叶节点,将路径的间隔符"->"添加到path中,并分别递归到左子节点、右子节点
- 若
to_string函数:将变量转换成string类型,具体可参考 std::to_string
代码实现:
void getPaths(TreeNode* root, string path, vector<string> &res) { | |
if (!root) return; | |
path += to_string(root->val); // 将节点值转换成 string 并添加到路径 | |
if (!root->left && !root->right) { // 叶节点 | |
res.push_back(path); // 将路径添加到目标数组 | |
return; | |
} | |
path += "->"; // 当前节点不是叶节点,继续递归遍历子节点 | |
getPaths(root->left, path, res); | |
getPaths(root->right, path, res); | |
} | |
vector<string> binaryTreePaths(TreeNode* root) { | |
vector<string> res; | |
getPaths(root, "", res); | |
return res; | |
} |
时间复杂度:,其中 为二叉树的节点数
空间复杂度:这里不考虑存放 res 的空间,但考虑 path 变量所需空间:
- 对于第 层,存放
path变量所需的空间复杂度为 ,其中, 小于等于二叉树的高度 - 平均情况下,二叉树的高度为 ,此时,总的空间复杂度为
- 最坏情况下,二叉树的高度为 ,此时,总的空间复杂度为
本题也可以采用迭代法来实现前序遍历,除了需要一个栈来模拟递归之外,还需要一个栈来存放对应的遍历路径,可参考 代码随想录:二叉树的所有路径 - 迭代法
此外,也可以使用层序遍历解题,具体可参考 力扣官方题解:二叉树的所有路径 - 方法二
# LeetCode 297. 二叉树的序列化与反序列化
297. Serialize and Deserialize Binary Tree
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式 。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:

输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = []
输出:[]
提示:
- 树中结点数在范围 内
-
Node.val
# Method: 前序遍历
算法思路:
序列化:按照前序遍历的顺序遍历二叉树,并将每个节点的数值转换成字符串记录下来。特别地,用 ',' 分隔每个节点的值,用 "1001" 标记空节点
反序列化:从字符串中提取出用 ',' 分隔的每一个数值,并按照前序遍历的顺序构造二叉树。特别地,如果遇到 "1001" ,则说明当前节点为空节点,无需继续构造其子树;如果遇到的不是 "1001" ,构造当前节点后还需递归构造其子树
代码实现:
class Codec { | |
public: | |
string serialize(TreeNode* root) { // 序列化 | |
string res = ""; | |
if (root == nullptr) { | |
res += to_string(1001); | |
res.push_back(','); | |
return res; | |
} | |
res += to_string(root->val); | |
res.push_back(','); | |
res += serialize(root->left); | |
res += serialize(root->right); | |
return res; | |
} | |
TreeNode* deserialize(string data) { // 反序列化 | |
int start = 0; | |
return helper(data, start); | |
} | |
TreeNode* helper(string& data, int& start) { // 从 data 的第 start 位开始构造二叉树 | |
TreeNode* root = nullptr; | |
int i = start; | |
while (i != data.size() && data[i] != ',') ++i; | |
string str(data.begin() + start, data.begin() + i); // 获取 ',' 之间的字符 | |
start = i + 1; // 更新起点 | |
if (str != "1001") { // 非空节点 | |
int num = stoi(str); | |
root = new TreeNode(num); | |
root->left = helper(data, start); | |
root->right = helper(data, start); | |
} | |
return root; | |
} | |
}; | |
// Your Codec object will be instantiated and called as such: | |
// Codec ser, deser; | |
// TreeNode* ans = deser.deserialize(ser.serialize(root)); |
时间复杂度:,其中 为二叉树的节点数
空间复杂度:,递归所需栈空间
# LeetCode 404. 左叶子之和
给定二叉树的根节点 root ,返回所有左叶子之和。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:24
解释:在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
示例 2:
输入:root = [1]
输出:0
提示:
- 节点数在 范围内
-
Node.val
# 思路
注意,本题计算的是 左叶节点 的和,而不是 左子节点 的和
若节点 node 是叶节点(即,不存在左右子节点),并且, node 是其父节点的左子节点,则节点 node 是左叶节点
例如,在 示例 1 中,值为 9 的节点和值为 15 的节点都是左叶节点
对于节点 node 而言,容易判断 node 是否为叶节点,但是,要想判断 node 是否为其父节点的左子节点,则并不容易
对此,我们可以退而求其次:判断每个 node 节点的左子节点(即, node->left )是否为叶节点
- 若是,则
node->left是左叶节点 - 若否,则
node->left不是左叶节点
# Method 1: 后序遍历
采用递归法,实现后序遍历(处理节点的顺序为:左 - 右 - 根)
算法思路:
-
递归函数的参数和返回值:
- 传入参数为树的根节点
root - 返回值为左叶节点的数值和,数据类型为
int
- 传入参数为树的根节点
-
递归的终止条件:遇到空节点
root,递归结束 -
单层递归的逻辑:
- 判断
root->left是否为叶节点- 若是,记录其数值
- 若否,分别递归到
root的左、右子树,计算左、右子树上的左叶节点数值和
- 计算以
root为根的所有左叶节点数值之和
- 判断
注意,
node的右子树也可能含有左子节点,例如 示例 1 中值为 15 的节点
代码实现:
int sumOfLeftLeaves(TreeNode* root) { | |
if (!root) return 0; | |
int midValue = 0; | |
if (root->left && !root->left->left && !root->left->right) //root->left 为左叶节点 | |
midValue = root->left->val; | |
return midValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right); | |
} |
时间复杂度:,其中 为二叉树的节点数
空间复杂度:,这里考虑了递归使用的栈空间,最坏情况下,树呈链状,深度为
# Method 2: 前序遍历
采用迭代法,实现前序遍历
代码实现:
int sumOfLeftLeaves(TreeNode* root) { | |
int ans = 0; | |
stack<TreeNode*> stk; | |
if (root) stk.push(root); | |
while (!stk.empty()) { | |
TreeNode* node = stk.top(); | |
stk.pop(); | |
if (node->left && !node->left->left && !node->left->right) | |
ans += node->left->val; | |
if (node->right) stk.push(node->right); // 右 | |
if (node->left) stk.push(node->left); // 左 | |
} | |
return ans; | |
} |
时间复杂度:,其中 为二叉树的节点数
空间复杂度:
# Method 3: 层序遍历
特别地,本题只需计算左叶节点的数值和,层序遍历时不必区分节点的层次。故而,只需将 Method 2 中的栈换成队列,即可实现层序遍历
代码实现:
int sumOfLeftLeaves(TreeNode* root) { | |
int ans = 0; | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
if (node->left && !node->left->left && !node->left->right) | |
ans += node->left->val; | |
if (node->left) que.push(node->left); // 左 | |
if (node->right) que.push(node->right); // 右 | |
} | |
return ans; | |
} |
时间复杂度:,其中 为二叉树的节点数
空间复杂度:
# LeetCode 429. N 叉树的层序遍历
LeetCode 429. N-ary Tree Level Order Traversal
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过 1000
- 树的节点总数在 之间
# 思路
从上到下、逐层遍历二叉树,每层按从左到右顺序遍历
对于 N 叉树 而言,每个节点可能有多个子节点,不失一般性地,指向子节点的指针存放在数组中
即,N 叉树的每个元素都有两个成员变量:节点的值 val 、存放子节点指针的数组 children
// N 叉树节点的定义 | |
class Node { | |
public: | |
int val; | |
vector<Node*> children; | |
Node() {} | |
Node(int _val) { | |
val = _val; | |
} | |
Node(int _val, vector<Node*> _children) { | |
val = _val; | |
children = _children; | |
} | |
}; |
# Method: 广度优先搜索
算法思路:
- 与 LeetCode 102. 二叉树的层序遍历 类似,利用队列存放待访问的节点
- 不同点在于:在 将子节点指针入队 的过程中,需要遍历子节点指针数组
children
代码实现:
vector<vector<int>> levelOrder(Node* root) { | |
vector<vector<int>> res; | |
queue<Node*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
vector<int> tmp; | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
Node* cur = que.front(); | |
que.pop(); | |
tmp.push_back(cur->val); | |
for (Node* child : cur->children) { // 子节点 | |
if (child) que.push(child); | |
} | |
} | |
res.push_back(tmp); | |
} | |
return res; | |
} |
时间复杂度:,其中 是节点个数
空间复杂度:
# LeetCode 437. 路径总和 III
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:

输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
输出:3
解释:和等于 8 的路径有 3 条,如图所示
示例 2:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:3
提示:
- 二叉树的节点个数的范围是 [0, 1000]
-
Node.val -
targetSum
# Method 1: 深度优先搜索
算法思路:
访问每一个节点 node,检测以 node 为起始节点且和为 targetSum 的路径数目,即:
- 定义 rootSum (root, sum) 表示以节点 root 为起点且满足路径总和为 val 的路径数目
- 递归遍历二叉树的每个节点 root,对每个节点 root 求 rootSum (root, sum),累加每个节点所求值
其中,rootSum (root, sum) 也是通过递归实现:
- 假设当前节点 root 的值为 val,初始化返回值 res 为 0
- 检查 val 是否等于 sum,若等于,则已经存在一条路径(节点 root 单独作为一条路径),即,res = res + 1
- 递归到左子树,计算以 root->left 为起点且满足路径和为 sum - val 的路径数,记作 leftRes
- 递归到右子树,计算以 root->left 为起点且满足路径和为 sum - val 的路径数,记作 rightRes
- 计算以 root 为起点且满足路径和为 sum 的路径总数,即:res = res + leftRes + rightRes
代码实现:
// 以 root 为起点的、和为 sum 的路径数 | |
int rootSum(TreeNode* root, long sum) { // 注意这里是 long sum (因为有特殊样例) | |
if (root == nullptr) return 0; | |
int res = 0; | |
if (root->val == sum) ++res; | |
res += rootSum(root->left, sum - root->val); | |
res += rootSum(root->right, sum - root->val); | |
return res; | |
} | |
// 在以 root 为根节点的二叉树中,计算和为 sum 的路径数 | |
int pathSum(TreeNode* root, int sum) { | |
if (root == nullptr) return 0; | |
int ans = rootSum(root, sum); // 以 root 为起点的、和为 sum 的路径数 | |
int left = pathSum(root->left, sum); // 递归到左子树,计算和为 sum 的路径数 | |
int right = pathSum(root->right, sum); // 递归到右子树,计算和为 sum 的路径数 | |
ans += left + right; | |
return ans; | |
} |
时间复杂度:,其中 为二叉树的节点数
- 遍历二叉树的每个节点,时间复杂度为
- 每个节点都要计算以该节点为起点的路径数目,时间复杂度为
空间复杂度:,递归所需栈空间
# Method 2: 前缀和
算法思路:
定义节点的前缀和:从根节点到当前节点的路径上所有节点的和(不包含当前节点),并利用哈希表 unordered_map<long long, int> prefix 记录每一个前缀和的出现次数
定义递归函数 helper () :在以 node 为根节点的二叉树中,计算 “ 以每个节点为路径终点、并且满足路径和为 targetSum” 的路径数,返回路径数总和
递归函数的参数:
TreeNode* node:当前节点int targetSum:目标和long long curSum:根节点到当前节点路径上所有节点之和(不包含当前节点)- 返回值:路径和为 targetSum 的路径条数
递归终止条件:node 为空节点,当前递归结束,返回 0
单层递归的逻辑:
- 将当前节点值计入路径和 curSum
- 计算以 node 为路径终点且满足路径和为 targetSum 的路径数:prefix [curSum - targetSum]
- 若存在节点 pi 使得根节点 root 到 pi 的路径和为 curSum - targetSum ,则节点 pi+1 到 node 的路径和一定为 targetSum
- 换言之,如果存在值为 curSum - targetSum 的前缀和,则一定存在 以 node 为终点且路径和为 targetSum 的路径,并且,前缀和的出现次数即为路径条数
- 将当前路径和 curSum 作为前缀和计入哈希表(以 curSum 为 key ,将对应的 value 加 1),以便递归到子树时使用
- 递归到左子树,计算以 node->left 为路径终点且满足路径和为 targetSum 的路径数
- 递归到左子树,计算以 node->right 为路径终点且满足路径和为 targetSum 的路径数
- 回溯:将当前路径和 curSum 从哈希表中删除(以 curSum 为 key ,将对应的 value 减 1)
- 计算路径总数,并返回结果
代码实现:
unordered_map<long long, int> prefix; | |
int helper(TreeNode* node, int targetSum, long long curSum) { | |
if (node == nullptr) return 0; | |
int ans = 0; | |
curSum += node->val; | |
ans += prefix[curSum - targetSum]; | |
++prefix[curSum]; | |
ans += helper(node->left, targetSum, curSum); | |
ans += helper(node->right, targetSum, curSum); | |
--prefix[curSum]; // 回溯 | |
return ans; | |
} | |
int pathSum(TreeNode* root, int targetSum) { | |
prefix[0] = 1; | |
return helper(root, targetSum, 0); | |
} |
时间复杂度:,其中 为二叉树的节点数。利用前缀和只需遍历一次二叉树
空间复杂度:,递归所需栈空间以及哈希表所需储存空间
# LeetCode 450. 删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key ,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 1:

输入:root = [5,3,6,2,4,null,7], key = 3
输出:[5,4,6,2,null,null,7]
解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。一个正确的答案是 [5,4,6,2,null,null,7], 如图所示。另一个正确答案是 [5,2,6,null,4,null,7]。

示例 2:
输入:root = [5,3,6,2,4,null,7], key = 0
输出:[5,3,6,2,4,null,7]
解释:二叉树不包含值为 0 的节点
示例 3:
输入:root = [], key = 0
输出:[]
提示:
- 节点数的范围
-
Node.val - 节点值唯一
root是合法的二叉搜索树-
key
进阶:要求算法时间复杂度为 , 为树的高度。
# 思路
建议先画示意图,结合图来分析
本题可能有以下情况:
-
二叉树中不存在值为
key的节点 -
二叉树中存在值为
key的节点,不妨记作nodenode的左、右子节点均为空,即,node是叶节点,直接删除node即可node的左子节点为空、右子节点不为空,在删除node时需要将其右子节点作为新的nodenode的左子节点为空、右子节点为空,在删除node时需要将其左子节点作为新的nodenode的左、右子节点均不为空,需要找到一个节点来承接node的左、右子节点
其中,针对 node 的左、右子节点均不为空 的情况:由于 node 左子树上所有节点值均小于 node ,而 node 右子树上所有节点值均大于 node ,可确定新的 node 节点为(二者选其一)
- 左子树上的最大节点(左子树的最右侧节点)
- 右子树上的最小节点(右子树的最左侧节点)
不妨取右子树上的最小节点,将其记作 successor ,在利用 successor 替换 node 的过程中需做以下考虑: successor 的右子树不一定为空,在从 successor 原本的位置上移除 successor 时,需妥善处理其右子树
- 如果
successor是node的右子节点(即,node->right就是node右子树上的最小节点),可以直接将successor的右子树作为node的右子树 - 否则,需要记录
successor的父节点(记作parent),将successor的右子树作为parent的左子树
除了上述方式外,也可以直接调用函数
deleteNode(root->right, successor->val),从以root->right为根的树上删除值为successor->val的节点
# Method 1: 递归
代码实现:
TreeNode* deleteNode(TreeNode* root, int key) { | |
if (!root) return nullptr; // 未找到 key | |
if (root->val > key) // 递归到左子树寻找 key | |
root->left = deleteNode(root->left, key); | |
if (root->val < key) // 递归到右子树寻找 key | |
root->right = deleteNode(root->right, key); | |
if (root->val == key) { //root 就是应删除的节点 | |
if (!root->left && !root->right) //root 为叶节点,直接删除 | |
return nullptr; | |
if (root->left && !root->right) // 用 root->left 替代 root | |
return root->left; | |
if (!root->left && root->right) // 用 root->right 替代 root | |
return root->right; | |
if (root->left && root->right) { // 从左、右子树中选出一个新的 root | |
TreeNode *successor = root->right; // 新的 root(初始化) | |
while (successor->left) // 取 root 右子树的最左侧节点 | |
successor = successor->left; | |
root->right = deleteNode(root->right, successor->val); // 删除 successor 原本的位置 | |
successor->left = root->left; // 将 root 左子树移动到 successor 上 | |
successor->right = root->right; // 将 root 右子树移动到 successor 上 | |
return successor; | |
} | |
} | |
return root; | |
} |
其中
TreeNode *successor = root->right; // 新的 root | |
while (successor->left) // 将 root 右子树的最左侧节点作为新的 root | |
successor = successor->left; | |
root->right = deleteNode(root->right, successor->val); // 删除 successor 原本的位置 |
可替换为
TreeNode *successor = root->right; // 新的 root (初始化) | |
TreeNode *parent = root; //successor 的父节点 | |
while (successor->left) { // 将 root 右子树的最左侧节点作为新的 root | |
parent = successor; | |
successor = successor->left; | |
} | |
if (parent == root) //successor 就是 root->right | |
parent->right = successor->right; // 将 successor 右子树作为 root 右子树 | |
else //successor 是 root->right 的左子树上节点 | |
parent->left = successor->right; // 将 successor 右子树作为 parent 左子树 |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用的栈空间
附注:在 代码随想录 中,针对
node的左、右子节点均不为空 的情况,其直接将node的左子树作为successor的左子树
# LeetCode 501. 二叉搜索树中的众数
501. Find Mode in Binary Search Tree
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:

输入:root = [1,null,2,2]
输出:[2]
示例 2:
输入:root = [0]
输出:[0]
提示:
- 树中节点的数目在范围 内
-
Node.val
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
# 思路
在二叉搜索树中,中序遍历可以得到有序序列
重复数字在中序遍历序列中必定是连续出现的
因此,可以先获得这棵树的中序遍历,然后扫描中序遍历序列,统计每个数字出现的个数,这样就可以找到出现次数最多的数字
# Method 1: 中序遍历(额外数组)
算法思路:
-
中序遍历二叉树,得到非递减的有序序列
nums -
定义
curCount记录当前数字的出现次数,maxCount表示当前统计到的最大出现次数,数组res记录出现的众数 -
遍历数组
nums的元素- 更新
curCount- 如果该元素是第 0 位元素,或者,该元素与上一位元素相等,
curCount自增 1 - 否则,意味着出现新数字,
curCount置为 1
- 如果该元素是第 0 位元素,或者,该元素与上一位元素相等,
- 更新
maxCount- 若
curCount == maxCount,当前数字的出现次数等于统计到的最大出现次数,将当前数字加入res - 若
curCount > maxCount,当前数字的出现次数大于统计到的最大出现次数,需将maxCount更新为curCount,清空res数组后再将当前元素加入res数组
- 若
- 更新
注:该算法在条件
curCount > maxCount或条件curCount == maxCount满足时就会更新res数组,而不只是在nums[i] != nums[i - 1]时更新res数组
代码实现:
void traversal(TreeNode *root, vector<int> &nums) { // 中序遍历 | |
if (!root) return; | |
traversal(root->left, nums); | |
nums.push_back(root->val); | |
traversal(root->right, nums); | |
} | |
vector<int> findMode(TreeNode* root) { | |
vector<int> nums; | |
traversal(root, nums); // 中序遍历序列 | |
int maxCount = 0; // 最大出现频率 | |
int curCount = 0; // 当前出现频率 | |
vector<int> res; // 目标数组 | |
for (int i = 0; i < nums.size(); i++) { | |
if (i == 0 || nums[i] == nums[i - 1]) curCount++; // 连续相同数字 | |
else curCount = 1; // 不相同数字,重新统计频率 | |
if (curCount > maxCount) { // 遇到出现频率更高的数字 | |
maxCount = curCount; // 更新最大出现频率 | |
res = {nums[i]}; // 清空此前记录的众数,并放入新的众数 | |
} else if (curCount == maxCount) { // 多个众数 | |
res.push_back(nums[i]); | |
} | |
} | |
return res; | |
} |
其中, res = {nums[i]}; 等价于
res.clear(); | |
res.push_back(nums[i]); |
算法的时间复杂度:,其中 是二叉树的节点数
- 遍历二叉树、遍历数组
nums的时间复杂度均为
算法的空间复杂度:,这里考虑了递归需要的栈空间、存放中序遍历结果的所需的空间
# Method 2: 中序遍历(无额外数组)
Method 1 先将二叉树节点值存放到中序遍历序列,然后再统计各数字的出现次数,这一过程使用了额外 的空间
实际上,也可以不存储中序遍历序列,直接在中序遍历二叉树的过程中操作
代码实现:
int curCount = 0; // 当前出现次数 | |
int maxCount = 0; // 最大出现次数 | |
TreeNode *pre = nullptr; // 前一个节点 | |
vector<int> res; // 存放众数 | |
void update(TreeNode *root) { // 更新 curCount , maxCount 和 res | |
if (pre == nullptr || root->val == pre->val) curCount++; | |
else curCount = 1; | |
if (curCount > maxCount) { | |
maxCount = curCount; | |
res = {root->val}; | |
} else if (curCount == maxCount) { | |
res.push_back(root->val); | |
} | |
pre = root; | |
} | |
void traversal(TreeNode *root) { // 中序遍历 | |
if (!root) return; | |
traversal(root->left); | |
update(root); | |
traversal(root->right); | |
} | |
vector<int> findMode(TreeNode* root) { | |
traversal(root); | |
return res; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,这里仅需考虑递归需要的栈空间
参考:
# LeetCode 513. 找树左下角的值
513. Find Bottom Left Tree Value
给定一个二叉树的 根节点 root ,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:

输入:root = [2,1,3]
输出:1
示例 2:

输入:root = [1,2,3,4,null,5,6,null,null,7]
输出:7
提示:
- 二叉树的节点个数的范围是
-
Node.val
# 思路
找出最后一行的最左侧节点的值:首先要是最后一行,然后是最左侧节点
# Method 1: 层序遍历
算法思路:逐层遍历,记录每层最左侧的节点(用下一层的记录覆盖上一层),遍历结束时,即得到最后一层的最左侧节点
代码实现:
int findBottomLeftValue(TreeNode* root) { | |
TreeNode* leftMost = new TreeNode(0); // 最左侧节点 | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
leftMost = que.front(); | |
int size = que.size(); | |
for (int i = 0; i < size; i++) { | |
TreeNode* tmp = que.front(); | |
que.pop(); | |
if (tmp->left) que.push(tmp->left); | |
if (tmp->right) que.push(tmp->right); | |
} | |
} | |
return leftMost->val; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
在遍历每一层时,可以按照 从右到左 的遍历顺序,于是,广度优先搜索所遍历的最后一个节点就是最底层最左边节点
# Method 2: 前序遍历
利用递归法计算二叉树的最大深度,并记录访问到的第一个具有最大深度的叶节点
算法思路:
-
递归函数
getValue的参数和返回值- 传入参数为根节点
root及其深度depth - 无返回值,返回值类型为
void
- 传入参数为根节点
-
递归的终止条件:遇到叶节点,当前递归结束
-
单层递归的逻辑:
- 若当前节点是叶节点
- 若当前节点深度大于此前所有节点的深度,则更新二叉树最大深度为当前节点的深度,并记录当前叶节点的值
- 当前递归结束,返回上一层递归
- 若当前节点不是叶节点,分别递归到左、右子节点
- 若当前节点是叶节点
注意:
- 最大深度
maxDepth和 最左侧节点值value是全局变量 - 递归函数的参数
depth采用拷贝赋值的方式传递,而不是以引用方式传递,这是为了递归的回溯
代码实现:
int maxDepth = INT_MIN; // 最大深度 | |
int value = 0; // 最大深度最左侧节点值 | |
void getValue(TreeNode* root, int depth) { // 查找以 root 为根的树底层最左侧节点 | |
if (!root->left && !root->right) { //root 为叶节点 | |
if (depth > maxDepth) { // 遍历到更大深度,更新 maxDepth 以及 value | |
maxDepth = depth; | |
value = root->val; | |
} | |
return; //root 为叶节点,不再向下遍历 | |
} | |
if (root->left) getValue(root->left, depth + 1); // 递归到左子树 | |
if (root->right) getValue(root->right, depth + 1); // 递归到右子树 | |
return; | |
} | |
int findBottomLeftValue(TreeNode* root) { | |
getValue(root, 1); | |
return value; | |
} |
补充说明:具有最大深度的节点一定是在最底层,这一点容易理解。但是,为什么可以找到最左侧的节点呢?
- 对于具有相同深度的两个节点,左侧节点的访问 / 处理一定先于右侧节点(无论是采用何种深度优先遍历方式)
- 在访问到第一个具有最大深度的节点(即,最底层的最左侧节点)时,
maxDepth和value均被更新。此后,访问到最底层的其余节点时,depth > maxDepth这一条件并不满足,value也就不会被更新。故而,value是最底层最左侧节点的值
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,考虑了递归使用的栈空间
# LeetCode 515. 在每个树行中找最大值
LeetCode 515. Find Largest Value in Each Tree Row
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例 1:

输入:root = [1,3,2,5,3,null,9]
输出:[1,3,9]
示例 2:
输入:root = [1,2,3]
输出:[1,3]
提示:
- 二叉树的节点个数的范围是
-
Node.val
# 思路
与 LeetCode 102. 二叉树的层序遍历 类似
逐层、从左到右遍历,利用队列存放待访问的节点
在遍历过程中,只需将 每一层节点值的最大值 添加到目标数组
# Method: 广度优先搜索
代码实现:
vector<int> largestValues(TreeNode* root) { | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
vector<int> ans; | |
while (!que.empty()) { | |
int size = que.size(); | |
int value = que.front()->val; // 每一行的最大值 | |
for (int i = 0; i < size; i++) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
if (node->val > value) value = node->val; // 查找最大值 | |
if (node->left) que.push(node->left); | |
if (node->right) que.push(node->right); | |
} | |
ans.push_back(value); // 将最大值添加到目标数组 | |
} | |
return ans; | |
} |
时间复杂度:,其中 是节点个数
空间复杂度:
# LeetCode 530. 二叉搜索树的最小绝对差
530. Minimum Absolute Difference in BST
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:

输入:root = [4,2,6,1,3]
输出:1
示例 2:

输入:root = [1,0,48,null,null,12,49]
输出:1
提示:
- 树中节点的数目范围是
-
Node.val
说明:本题与 LeetCode 783 相同
# 思路
本题类似于 LeetCode 98. 验证二叉搜索树
只需在中序遍历过程中计算前一个节点值和后一个节点值之差即可
# Method: 中序遍历
代码实现:
void helper(TreeNode *root, int &minDif, int &preValue) { // 计算 root 与前一个节点值的绝对差,并更新最小绝对差 | |
if (!root) return; | |
helper(root->left, minDif, preValue); // 左 | |
minDif = min(abs(root->val - preValue), minDif); // 根 | |
preValue = root->val; | |
helper(root->right, minDif, preValue); // 右 | |
} | |
int getMinimumDifference(TreeNode* root) { | |
int minDif = INT_MAX; // 最小差值 | |
int preValue = INT_MAX; // 前一个节点的值 | |
helper(root, minDif, preValue); | |
return minDif; | |
} |
也可以写成:
int minDif = INT_MAX; // 最小绝对差 | |
TreeNode *pre = nullptr; // 前一个节点 | |
void helper(TreeNode *root) { | |
if (!root) return; | |
helper(root->left); // 左 | |
if (pre != nullptr) | |
minDif = min(abs(root->val - pre->val), minDif); // 根 | |
pre = root; | |
helper(root->right); // 右 | |
} | |
int getMinimumDifference(TreeNode* root) { | |
helper(root); | |
return minDif; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用栈空间
# LeetCode 538. 把二叉搜索树转换为累加树
538. Convert BST to Greater Tree
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
示例 1:

输入:root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1]
输出:[1,null,1]
提示:
- 树中的节点数范围为
-
node.val - 树中的所有值 互不相同
- 给定的树为二叉搜索树
说明: 本题与 LeetCode 1038 相同
# Method: 递归
# 算法思路
二叉搜索树的中序遍历是一个单调递增的有序序列
若按照 右 - 根 - 左 的顺序遍历,则会得到一个单调递减的有序序列
本题要求将 每个节点的值 修改为 原来的节点值加上所有大于它的节点值之和 ,可以按照 右 - 根 - 左 的顺序遍历二叉树,记录过程中的节点值之和,并不断更新遍历到的节点值
# 代码实现
void traversal(TreeNode *root, int &sum) { // 按 右 - 根 - 左 顺序遍历 | |
if (!root) return; | |
traversal(root->right, sum); // 先递归右子树,统计 所有 值大于 root->val 的节点 之和 | |
sum += root->val; // 统计所有 值大于等于 root->val 的节点 之和 | |
root->val = sum; // 将 root->val 更新为 sum | |
traversal(root->left, sum); // 递归到左子树 | |
} | |
TreeNode* convertBST(TreeNode* root) { | |
int sum = 0; // 累加和 | |
traversal(root, sum); | |
return root; | |
} |
# 复杂度分析
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用的栈空间
参考:
# LeetCode 543. 二叉树的直径
给定一棵二叉树,你需要计算它的直径长度。
一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
注意: 两结点之间的路径长度是以它们之间边的数目表示
示例 1:

输入:root = [1,2,3,4,5]
输出:3
解释:路径 [4,2,1,3] 或者 [5,2,1,3]
示例 2:
输入:root = [1,2]
输出:1
提示:
- 节点数的范围是
-
Node.val
# Method: 递归
# 算法思路
定义一个递归函数 int helper(TreeNode* root) ,用于计算 以 root 为起点、向下延伸的路径的最大长度(即,最大边数,因为两节点之间的路径长度是以它们之间边的数目表示的),即,以 root 为根的二叉树的最大深度减 1
任意节点 node 都有一条从其左子树到右子树的最长路径(记作 route ),其路径长度(边数)为左子树最大深度 + 右子树最大深度 - 2 ,即, helper(node->left) + helper(node->right)
因此,遍历二叉树每一个节点并比较其对应的路径 route 的长度,即可得到整个二叉树中最长路径的长度
# 代码实现
int ans = 0; // 路径的最大长度 | |
int helper(TreeNode* root) { | |
if (root == nullptr) return 0; | |
int leftEdges = helper(root->left); // 以左子节点为起点向下延伸的最长路径的长度(边数) | |
int rightEdges = helper(root->right); // 以右子节点为起点向下延伸的最长路径的长度(边数) | |
ans = max(ans, leftEdges + rightEdges); // 从左子树深度最大的节点到右子树深度最大的节点 | |
return max(leftEdges, rightEdges) + 1; // 以 root 为起点向下延伸的最长路径的长度(边数) | |
} | |
int diameterOfBinaryTree(TreeNode* root) { | |
helper(root); | |
return ans; | |
} |
# 复杂度分析
时间复杂度:,其中 为二叉树的节点数。每个节点均遍历一次
空间复杂度:,递归所需栈空间
# LeetCode 572. 另一棵树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。 tree 也可以看做它自身的一棵子树。
示例 1:

输入:root = [3,4,5,1,2], subRoot = [4,1,2]
输出:true
示例 2:

输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2]
输出:false
提示:
root树上的节点数量范围是subRoot树上的节点数量范围是-
root.val -
subRoot.val
# Method 1: 深度优先遍历 + 暴力匹配
算法思路:按照前序遍历的顺序枚举树 root 中的每一个节点,判断以这个节点为根的树是否和树 subRoot 相同,其中,判断两树是否相同可参考 LeetCode 100. 相同二叉树
代码实现:
bool isSameTree(TreeNode *root1, TreeNode *root2) { // 判断以 root1 为根的树是否相同于以 root2 为根的树 | |
if (!root1 && !root2) return true; | |
if (!root1 || !root2) return false; | |
if (root1->val != root2->val) return false; | |
return isSameTree(root1->left, root2->left) && isSameTree(root1->right, root2->right); | |
} | |
bool isSubtree(TreeNode* root, TreeNode* subRoot) { | |
if (!root) return false; //root 为空,subRoot 不是 root 的子树 | |
if (isSameTree(root, subRoot)) return true; // 以 root 为根的树 相同于 以 subRoot 为根的树 | |
return isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot); //root 递归到左、右子节点 | |
} |
时间复杂度:,其中, 和 分别是树 root 和树 subRoot 的节点个数
- 最坏情况下,需要遍历树
root中每个节点,时间复杂度为 - 判断两树是否相同 的时间复杂度为
空间复杂度:,其中, 和 分别是树 root 和树 subRoot 的深度。这里考虑了递归调用栈,任意时刻下栈使用的最大空间为
# Method 2: 深度优先遍历 + KMP 匹配
先验知识:一棵子树上的节点在深度优先搜索序列(前序遍历)中是连续的
因此,可以利用前序遍历得到树 root 和树 subRoot 的节点序列,分别记作 s 和 t ,然后判断 t 是否为 s 的子串
-
但需注意,仅仅是前序遍历无法唯一确定一棵二叉树
-
例如,
root由两个点组成:1 是根,2 是 1 的左子节点;subRoot也由两个点组成:1 是根,2 是 1 的右子节点,此时,树root和subRoot的前序遍历序列相同,但subRoot并不是root的某一棵子树 -
由此可见:“
t是s的子串 ” 是 “subRoot是root的子树 ” 的必要不充分条件 -
对此,可以引入两个空值
lNull和rNull,当前序遍历遇到空的左子节点、空的右子节点时,分别在节点序列中放入lNull和rNull值,由此,可以唯一确定一棵二叉树
判断 t 是否为 s 的子串,可以采用暴力匹配,也可以使用 KMP 或者 Rabin-Karp 算法
可参考 KMP 算法 和 力扣官方题解:另一棵树的子树 - 方法二
# LeetCode 589. N 叉树的前序遍历
589. N-ary Tree Preorder Traversal
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:[1,3,5,6,2,4]
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[1,2,3,6,7,11,14,4,8,12,5,9,13,10]
提示:
- 节点总数在范围 内
-
Node.val - n 叉树的高度小于或等于
进阶:递归法很简单,你可以使用迭代法完成此题吗?
# 思路
类似于 144. 二叉树的前序遍历
# Method 1: 递归
算法思路:按照 根 - 左 - 右 的顺序访问节点,并将节点的值添加到目标数组
代码实现:
void DFS(Node* root, vector<int> &res) { | |
if (root == nullptr) return; | |
res.push_back(root->val); // 将 root 的值添加到数组 res | |
for (auto node : root->children) // 访问子节点 | |
DFS(node, res); | |
} | |
vector<int> preorder(Node* root) { | |
vector<int> res; | |
DFS(root, res); | |
return res; | |
} |
# Method 2: 迭代
算法思路:子节点须按从右到左的顺序依次放入栈中,以使得子节点按从左到右顺序出栈,以实现 根 - 左 - 右 顺序访问
代码实现:
vector<int> preorder(Node* root) { | |
vector<int> res; | |
stack<Node*> stk; | |
if (root) stk.push(root); | |
Node* tmp = new Node(0); | |
while (!stk.empty()) { | |
tmp = stk.top(); | |
stk.pop(); | |
res.push_back(tmp->val); | |
int size = tmp->children.size(); | |
for (int i = size - 1; i >= 0; i--) { // 逆序入栈,顺序出栈 | |
if (tmp->children[i]) stk.push(tmp->children[i]); | |
} | |
} | |
return res; | |
} |
时间复杂度:,其中 是树的节点数
空间复杂度:
# LeetCode 590. N 叉树的后序遍历
LeetCode 590. N-ary Tree Postorder Traversal
Given the root of an n-ary tree, return the postorder traversal of its nodes' values.
# 思路
类似于 145. 二叉树的后序遍历
# Method 1: 递归
算法思路:按照 左 - 右 - 根 的顺序访问节点,并将节点的值添加到目标数组
代码实现:
void DFS(Node* root, vector<int> &res) { // 左 - 右 - 根 | |
if (root == nullptr) return; | |
int size = root->children.size(); | |
for (int i = 0; i < size; i++) | |
DFS(root->children[i], res); | |
res.push_back(root->val); | |
} | |
vector<int> postorder(Node* root) { | |
vector<int> res; | |
DFS(root, res); | |
return res; | |
} |
# Method 2: 迭代
算法思路:
-
按照 根 - 右 - 左 的顺序访问节点,并将节点的值添加到目标数组
-
最后将目标数组反转,即为所求
代码实现:
vector<int> postorder(Node* root) { | |
vector<int> res; | |
stack<Node*> stk; | |
if (root) stk.push(root); | |
Node* tmp = new Node(0); | |
while (!stk.empty()) { | |
tmp = stk.top(); | |
stk.pop(); | |
res.push_back(tmp->val); | |
int size = tmp->children.size(); | |
for (int i = 0; i < size; i++) // 节点按从左到右顺序入栈,按逆序出栈 | |
if (tmp->children[i]) stk.push(tmp->children[i]); | |
} | |
reverse(res.begin(), res.end()); | |
return res; | |
} |
时间复杂度:,其中 是树的节点数
空间复杂度:
# LeetCode 617. 合并二叉树
LeetCode 617. Merge Two Binary Trees
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:

输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
示例 2:
输入:root1 = [1], root2 = [1,2]
输出:[2,2]
提示:
- 两棵树中的节点数目范围为
-
Node.val
# Method: 递归
算法思路:
-
确定递归的参数和返回值
- 参数:两棵二叉树的根节点
root1和root2 - 返回值:合并后的根节点
- 参数:两棵二叉树的根节点
-
递归终止条件
- 若
root1为空,合并结果即为root2,返回root2 - 若
root2为空,合并结果即为root1,返回root1
- 若
-
单层递归的逻辑
- 合并节点:计算
root1->val和root2->val的和 - 递归,合并左子树
- 递归,合并右子树
- 返回合并结果
- 合并节点:计算
代码实现:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) { | |
if (!root1) return root2; | |
if (!root2) return root1; | |
TreeNode *root = new TreeNode(); | |
root->val = root1->val + root2->val; // 合并节点 | |
root->left = mergeTrees(root1->left, root2->left); // 递归,合并左子树 | |
root->right = mergeTrees(root1->right, root2->right); // 递归,合并右子树 | |
return root; | |
} |
时间复杂度:,其中 和 分别是两个二叉树的节点数
- 对两个二叉树同时进行深度优先搜索,只有当两个二叉树中的对应节点都不为空时才会对该节点进行显性合并操作
空间复杂度:,这里考虑了递归使用的栈空间
- 递归调用的层数不会超过较小二叉树的高度,最坏情况下,二叉树的高度等于节点数
参考:
# LeetCode 637. 二叉树的层平均值
LeetCode 637. Average of Levels in Binary Tree
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 以内的答案可以被接受。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11
示例 2:

输入:root = [3,9,20,15,7]
输出:[3.00000,14.50000,11.00000]
提示:
- 树中节点数量范围为
-
Node.val
# 思路
层次遍历
对于每一层,只需将 该层所有节点的平均值 添加到目标数组
注意,均值为 double 型
# Method: 广度优先搜索
算法流程:与 LeetCode 102. 二叉树的层序遍历 类似,区别在于,只需记录每一层节点值的平均值
代码实现:
vector<double> averageOfLevels(TreeNode* root) { | |
vector<double> res; | |
queue<TreeNode*> que; | |
if (root) que.push(root); | |
while (!que.empty()) { | |
int size = que.size(); | |
double sum = 0; //double 型 | |
for (int i = 0; i < size; i++) { | |
TreeNode* node = que.front(); | |
que.pop(); | |
sum += node->val; | |
if (node->left) que.push(node->left); | |
if (node->right) que.push(node->right); | |
} | |
res.push_back(sum / size); // 仅记录每一层节点的平均值 | |
} | |
return res; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# LeetCode 654. 最大二叉树
给定一个不重复的整数数组 nums 。最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为 nums 中的最大值。
- 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
- 返回
nums构建的 最大二叉树 。
示例 1:

输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
示例 2:

输入:nums = [3,2,1]
输出:[3,null,2,null,1]
提示:
-
nums.length -
nums[i] nums中的所有整数 互不相同
# Method: 递归
算法思路:定义递归函数 constructTree(nums, left, right) ,找出数组在区间 [left, right) 内的最大值,利用最大值左侧元素构造左子树、最大值右侧元素构造右子树
注意:类似的用数组构造二叉树的题目,每次分割时尽量不要定义新数组,而是通过下标索引直接在原数组上操作,这样可以节约时间和空间上的开销
代码实现:
TreeNode *constructTree(vector<int>& nums, int left, int right) { // 区间为 [left, right) | |
if (left == right) return nullptr; // 允许空节点进入递归,终止条件为:遇到空数组 | |
int maxValueIndex = left; // 最大值对应的索引 | |
for (int i = left; i < right; i++) { | |
if (nums[i] > nums[maxValueIndex]) | |
maxValueIndex = i; | |
} | |
TreeNode *root = new TreeNode(nums[maxValueIndex]); // 根节点 | |
root->left = constructTree(nums, left, maxValueIndex); // 左子节点 | |
root->right = constructTree(nums, maxValueIndex + 1, right); // 右子节点 | |
return root; | |
} | |
TreeNode* constructMaximumBinaryTree(vector<int>& nums) { | |
return constructTree(nums, 0, nums.size()); | |
} |
时间复杂度:,其中 是二叉树的节点数
constructTree函数一共被调用 次,时间复杂度为- 每次调用需要遍历当前的
[left, right)区间- 平均情况下,时间复杂度为
- 最坏情况下,
nums本身有序,时间复杂度为
空间复杂度:,考虑了递归使用的栈空间
参考:
# LeetCode 669. 修剪二叉搜索树
669. Trim a Binary Search Tree
给你二叉搜索树的根节点 root ,同时给定最小边界 low 和最大边界 high 。通过修剪二叉搜索树,使得所有节点的值在 [low, high] 中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
示例 1:

输入:root = [1,0,2], low = 1, high = 2
输出:[1,null,2]
示例 2:

输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3
输出:[3,2,null,1]
提示:
- 树中节点数范围为
-
Node.val - 树中每个节点的值都是 唯一 的
- 题目数据保证输入是一棵有效的二叉搜索树
-
lowhigh
# 思路
若节点 node 的值小于 low ,则节点 node 应删除,并且
node左子树上节点的值一定小于low,因此左子树也应删除node右子树上节点的值可能落在[low, high]外,因此需要修剪右子树,用修剪过的右子树接替node的位置
若节点 node 的值大于 high ,则节点 node 应删除,并且
node右子树上节点的值一定大于high,因此右子树也应删除node左子树上节点的值可能落在[low, high]外,因此需要修剪左子树,用修剪过的左子树接替node的位置
若节点 node 的值落在 [low, high] 内,需进一步修剪 node 的左子树、右子树
# Method: 递归
代码实现:
TreeNode* trimBST(TreeNode* root, int low, int high) { | |
if (!root) return nullptr; | |
if (root->val < low) //root 及其左子树应移除 | |
return trimBST(root->right, low, high); // 修剪右子树,并用右子树接替 root 的位置 | |
if (root->val > high) //root 及其右子树应移除 | |
return trimBST(root->left, low, high); // 修剪左子树,并用左子树接替 root 的位置 | |
root->left = trimBST(root->left, low, high); // 递归到左子树 | |
root->right = trimBST(root->right, low, high); // 递归到右子树 | |
return root; | |
} |
注意:以下代码
if (root->val < low) //root 及其左子树应移除 | |
return trimBST(root->right, low, high); // 修剪右子树,并用右子树接替 root 的位置 | |
if (root->val > high) //root 及其右子树应移除 | |
return trimBST(root->left, low, high); // 修剪左子树,并用左子树接替 root 的位置 |
不能被替换成
if (root->val < low) | |
return root->right; // 这里直接返回了 root 右子树,并未对其修剪(此后的遍历也不会再修剪该子树) | |
if (root->val > high) | |
return root->left); // 这里直接返回了 root 左子树,并未对其修剪(此后的遍历也不会再修剪该子树) |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用的栈空间
参考:代码随想录
# LeetCode 700. 二叉搜索树中的搜索
700. Search in a Binary Search Tree
给定二叉搜索树(BST)的根节点 root 和一个整数值 val 。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
示例 1:

输入:root = [4,2,7,1,3], val = 2
输出:[2,1,3]
示例 2:

输入:root = [4,2,7,1,3], val = 5
输出:[]
提示:
- 数中节点数范围为
-
Node.val root是二叉搜索树-
val
# 思路
二叉搜索树是一个有序树
- 若它的左子树非空,则左子树上所有节点的值均小于根节点值
- 若它的右子树非空,则右子树上所有节点的值均大于根节点值
- 左、右子树也分别为二叉搜索树
# Method 1: 递归
算法思路:
-
确定递归参数和返回值
- 参数:根节点
root与 目标值val - 返回值:目标值对应的节点
- 参数:根节点
-
递归终止条件:
root为空,未找到val,返回NULL,递归结束 -
单层递归的逻辑
- 若
root->val == val,找到val,返回root - 若
root->val > val,搜索左子树 - 若
root->val < val,搜索右子树 - 如果没有搜索到,返回
NULL
- 若
代码实现:
TreeNode* searchBST(TreeNode* root, int val) { | |
if (!root) return nullptr; //root 为空,未找到 val | |
if (root->val == val) return root; //root 节点值等于 val ,找到 val | |
if (root->val > val) return searchBST(root->left, val); // 递归到左子树中搜索 | |
return searchBST(root->right, val); // 递归到右子树中搜索 | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
# Method 2: 迭代
由于二叉搜索树的特殊性(节点的有序性),无需辅助栈或者队列就可实现迭代法
代码实现:
TreeNode* searchBST(TreeNode* root, int val) { | |
while (root != nullptr) { | |
if (root->val < val) root = root->right; | |
else if (root->val > val) root = root->left; | |
else return root; | |
} | |
return nullptr; | |
} |
时间复杂度:
空间复杂度:
# LeetCode 701. 二叉搜索树中的插入操作
701. Insert into a Binary Search Tree
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
示例 1:

输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
解释:另一个满足题目要求可以通过的树是:

示例 2:
输入:root = [40,20,60,10,30,50,70], val = 25
输出:[40,20,60,10,30,50,70,null,null,25]
示例 3:
输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5
输出:[4,2,7,1,3,5]
提示:
- 树中的节点数范围为
-
Node.val - 所有值
Node.val互不相同 -
val - 保证
val在原始 BST 中不存在
# 思路
根据 root 节点值与 val 的大小关系,确定将 val 插入到 root 的哪一棵子树
- 如果该子树不为空,则问题转化为 将
val插入到root子树的子树上 - 如果子树为空,则新建一个值为
val的节点,将其链接到父节点root上
# Method 1: 递归
# 写法一:有返回值
代码实现:
TreeNode* insertIntoBST(TreeNode* root, int val) { | |
if (root == nullptr) { // 空节点,亦即 val 的插入点 | |
root = new TreeNode(val); | |
return root; | |
} | |
if (root->val > val) //val 小于 root ,应将其插入到左子树 | |
root->left = insertIntoBST(root->left, val); | |
if (root->val < val) //val 大于 root ,应将其插入到右子树 | |
root->right = insertIntoBST(root->right, val); | |
return root; | |
} |
注意, root->left = insertIntoBST(root->left, val); 和 root->right = insertIntoBST(root->right, val); 这两个命令是为了将插入的节点与其父节点建立连接
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用栈空间
# 写法二:无返回值
算法思路:在不设定递归函数返回值的情况下,需要记录父节点,当找到插入节点的位置时,直接让其父节点指向插入节点。其中,新节点是作为左子节点还是右子节点,取决于父节点的值与 val 的大小关系
代码实现:
TreeNode *parent = nullptr; | |
void helper(TreeNode *root, int val) { | |
if (root == nullptr) { | |
TreeNode *node = new TreeNode(val); | |
if (parent->val > val) parent->left = node; | |
else parent->right = node; | |
return; | |
} | |
parent = root; | |
if (root->val > val) helper(root->left, val); | |
if (root->val < val) helper(root->right, val); | |
} | |
TreeNode* insertIntoBST(TreeNode* root, int val) { | |
if (root == nullptr) return new TreeNode(val); | |
helper(root, val); | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:,递归使用栈空间
参考:代码随想录
# Method 2: 迭代
算法思路:利用迭代法实现插入节点
# 写法一
代码实现:
TreeNode* insertIntoBST(TreeNode* root, int val) { | |
if (!root) return new TreeNode(val); | |
TreeNode *node = root; | |
while (node != nullptr) { | |
if (node->val > val) { // 应插入到 node 的左子树 | |
if (node->left != nullptr) { | |
node = node->left; | |
} else { | |
node->left = new TreeNode(val); | |
break; | |
} | |
} else { // 应插入到 node 的右子树 | |
if (node->right != nullptr) { | |
node = node->right; | |
} else { | |
node->right = new TreeNode(val); | |
break; | |
} | |
} | |
} | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
参考:力扣官方题解
# 写法二
代码实现:
TreeNode* insertIntoBST(TreeNode* root, int val) { | |
if (root == NULL) { | |
TreeNode* node = new TreeNode(val); | |
return node; | |
} | |
TreeNode* cur = root; | |
TreeNode* parent = root; // 记录上一个节点,以便链接新节点 | |
while (cur != NULL) { | |
parent = cur; | |
if (cur->val > val) cur = cur->left; | |
else cur = cur->right; | |
} | |
TreeNode* node = new TreeNode(val); | |
if (val < parent->val) parent->left = node; | |
else parent->right = node; | |
return root; | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
参考:代码随想录
# LeetCode 94. 二叉树的中序遍历
LeetCode 94. Binary Tree Inorder Traversal
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:

输入:root = [1,2]
输出:[2,1]
示例 3:

输入:root = [1,null,2]
输出:[1,2]
提示:
- 树中节点数目在范围
[0, 100]内 -
Node.val
进阶:递归算法很简单,你可以通过迭代算法完成吗?
# 思路
按照访问左子树 —— 根节点 —— 右子树的方式遍历这棵树,左子树或者右子树按照同样的方式遍历
# Method 1: 递归
代码实现:
vector<int> inorderTraversal(TreeNode* root) { | |
vector<int> res; | |
inorder(root,res); // 中序遍历 | |
return res; | |
} | |
void inorder(TreeNode* root, vector<int> &res) { | |
if (root == nullptr) return; | |
inorder(root->left, res); // 左子树 | |
res.push_back(root->val); // 当前节点 | |
inorder(root->right, res); // 右子树 | |
} |
时间复杂度:,其中, 为二叉树的节点个数
空间复杂度:,栈的开销,这里忽略了目标数组所需空间
# Method 2: 迭代
按照中序遍历规则,遍历到某个节点时,并不直接获取它的值,而是先遍历它的左子树,然后才将它本身的值加入到目标数组中,然后再遍历右子树(注意,左、右子树的遍历规则也是如此)
换而言之,中序遍历首先要一层一层向下访问,直到到达左子树的最底部,才开始获取节点的值
算法流程:
-
定义一个空的栈
stk,定义一个指针cur指向当前遍历的节点 -
执行循环(直到
stk为空 且cur为空指针):- 执行以下循环,直到
cur为空指针(此时,栈顶 是 指向最底层节点的指针)- 将
cur压入栈 - 令
cur指向 左子节点,即,cur = cur->left;
- 将
- 更新
cur = stk.top(),使得cur指向最底层节点 - 将节点的值添加到目标数组,并将栈顶元素弹出
- 更新
cur = cur->right,即,令cur指向其右子节点,以继续遍历
- 执行以下循环,直到
-
循环结束时,所有节点均已被访问,返回目标数组
有点抽象,建议根据实例模拟一遍,例如:
代码实现:
vector<int> inorderTraversal(TreeNode* root) { | |
vector<int> res; | |
stack<TreeNode*> stk; | |
TreeNode* cur = root; | |
while (!stk.empty() || cur != nullptr) { | |
while (cur != nullptr) { // 遍历至 cur 左子树的最底部 | |
stk.push(cur); | |
cur = cur->left; | |
} | |
cur = stk.top(); // 最左侧的节点(它不存在左子节点) | |
res.push_back(cur->val); // 将节点的值加入到目标数组 | |
stk.pop(); // 出栈 | |
cur = cur->right; // 遍历右子树 | |
} | |
return res; | |
} |
时间复杂度:
空间复杂度:
参考:
# LeetCode 96. 不同的二叉搜索树
96. Unique Binary Search Trees
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:

输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
提示:
- n
# 思路
定义以下两个函数:
- :长为 的序列所能构成的二叉搜索树的个数
- :长为 的序列所能构成的以 为根节点的二叉搜索树的个数
对于长为 的序列而言,可以遍历每个数字 :将数字 作为根节点,将 序列作为左子树,将 序列作为右子树。因此,
注意, 只依赖于序列的长度,而与序列中的内容无关。因此,将数字 作为根节点时,有:
- 利用 序列构造左子树,序列长度为 ,能构造出 棵不同的左子树(二叉搜索树)
- 利用 序列构造右子树,序列长度为 ,能构造出 棵不同的右子树(二叉搜索树)
左子树与右子树的构造是相互独立的,因此,以 为根节点的二叉搜索树个数,应为 可构造的左子树个数 与 可构造的右子树个数 之积,即,
因此, 的递推公式为
当序列长度为 时,只能构造出一棵树,即
参考:
# Method: 动态规划
代码实现:
int numTrees(int n) { | |
vector<int> dp(n + 1, 0); | |
dp[0] = 1; | |
for (int i = 1; i <= n; i++) { | |
for (int j = 1; j <= i; j++) { | |
dp[i] += dp[j - 1] * dp[i - j]; | |
} | |
} | |
return dp[n]; | |
} |
时间复杂度:
空间复杂度:
# LeetCode 98. 验证二叉搜索树
98. Validate Binary Search Tree
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:

输入:root = [2,1,3]
输出:true
示例 2:

输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
提示:
- 树中节点数目范围为
-
Node.val
# Method 1: 中序遍历
二叉搜索树的中序遍历序列是一个有序序列(升序序列)
因此,可通过判断中序遍历序列是否有序来判断该二叉树是否为二叉搜索树
# 写法一
把二叉树转变为数组,判断数组元素按升序排列
代码实现:
void midorder(TreeNode *root, vector<int> &nums) { // 中序遍历 | |
if (!root) return; | |
midorder(root->left, nums); | |
nums.push_back(root->val); | |
midorder(root->right, nums); | |
} | |
bool isValidBST(TreeNode* root) { | |
vector<int> nums; | |
midorder(root, nums); | |
for (int i = 1; i < nums.size(); i++) { // 检查中序遍历数组是否按升序排列 | |
if (nums[i] <= nums[i - 1]) return false; | |
} | |
return true; | |
} |
# 写法二
可以直接在中序遍历的过程中判断前一个节点的值是否小于后一个节点的值,以判断中序遍历序列是否有序
代码实现:
TreeNode *pre = nullptr; // 前一个节点 | |
bool isValidBST(TreeNode* root) { | |
if (!root) return true; | |
if (!isValidBST(root->left)) return false; // 验证左子树是否为二叉搜索树 | |
if (pre && pre->val >= root->val) return false; // 检查中序遍历序列是否有序 | |
pre = root; // 更新 pre | |
return isValidBST(root->right); // 验证右子树是否为二叉搜索树 | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度:
中序遍历也可以由迭代法实现
# Method 2: 前序遍历
二叉搜索树的性质:
- 若二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值
- 若它的右子树不为空,则右子树上所有节点的值均大于它的根节点的值
- 它的左、右子树也为二叉搜索树
由此,可以设计一个递归函数 traversal(root, lowerBound, upperBound) 来递归判断:
- 如果
root节点的值不在(lowerBound, upperBound)范围内,说明不满足条件,直接返回 - 否则,继续递归调用检查它的左右子树是否满足,如果都满足才说明这是一棵二叉搜索树
算法思路:
-
确定递归的参数和返回值:
- 参数:根节点
TreeNode *root、节点取值的下界long long lowerBound、节点取值的上界long long upperBound - 返回值:所有节点取值是否都落在
(lowerBound, upperBound)范围内
- 参数:根节点
-
递归终止条件:空节点,返回
true,当前递归结束 -
单层递归的逻辑
- 若
root的值落在(lowerBound, upperBound)范围外,条件不满足,返回false - 递归到左子树,其中,节点取值的下界、上界分别为
lowerBound、root->val - 递归到右子树,其中,节点取值的下界、上界分别为
root->val、upperBound - 若左、右子树均满足条件,返回
true
- 若
注意到
Node.val可能取到 和 这两个值,需要将lowerBound和upperBound分别设定为long long型,并分别初始化为LONG_MIN和LONG_MAX,即,long long型的-inf和+inf(因为递归函数的检验范围(lowerBound, upperBound)是开区间,若取int型的INT_MIN和INT_MAX,则无法正确处理Node.val取 和 这两个值的情况)
代码实现:
bool traversal(TreeNode* root, long long lowerBound, long long upperBound) { | |
if (!root) return true; | |
if (root->val <= lowerBound || root->val >= upperBound) | |
return false; | |
bool left = traversal(root->left, lowerBound, root->val); | |
bool right = traversal(root->right, root->val, upperBound); | |
return left && right; | |
} | |
bool isValidBST(TreeNode* root) { | |
return traversal(root, LONG_MIN, LONG_MAX); | |
} |
时间复杂度:,其中 是二叉树的节点数
空间复杂度: