树:用来模拟具有树状结构性质的数据集合
二叉树 (Binary Tree):每个节点 最多有两个子树 的树结构,通常子树被称作 “左子树” 和 “右子树”
注意:二叉树必须严格区分左右子树,即使只有一棵子树,也要说明它是左子树还是右子树
# 二叉树的种类
# 满二叉树
满二叉树:一棵高度为 并具有 个节点的二叉树
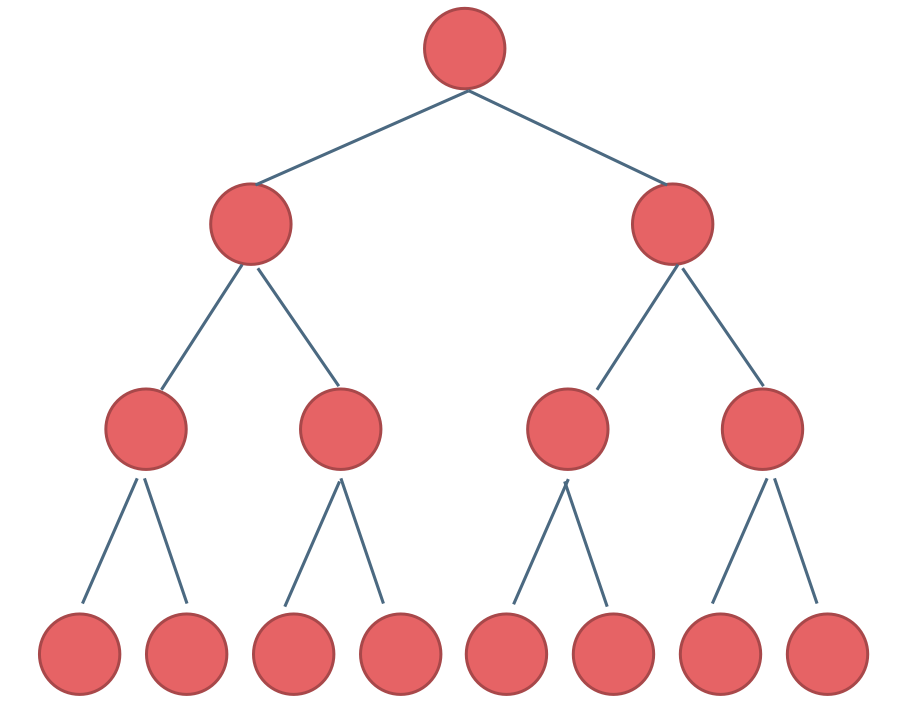
# 完全二叉树
完全二叉树:在满二叉树的最底层自右至左依次(注意:不能跳过任何一个节点)去掉若干个节点得到的二叉树
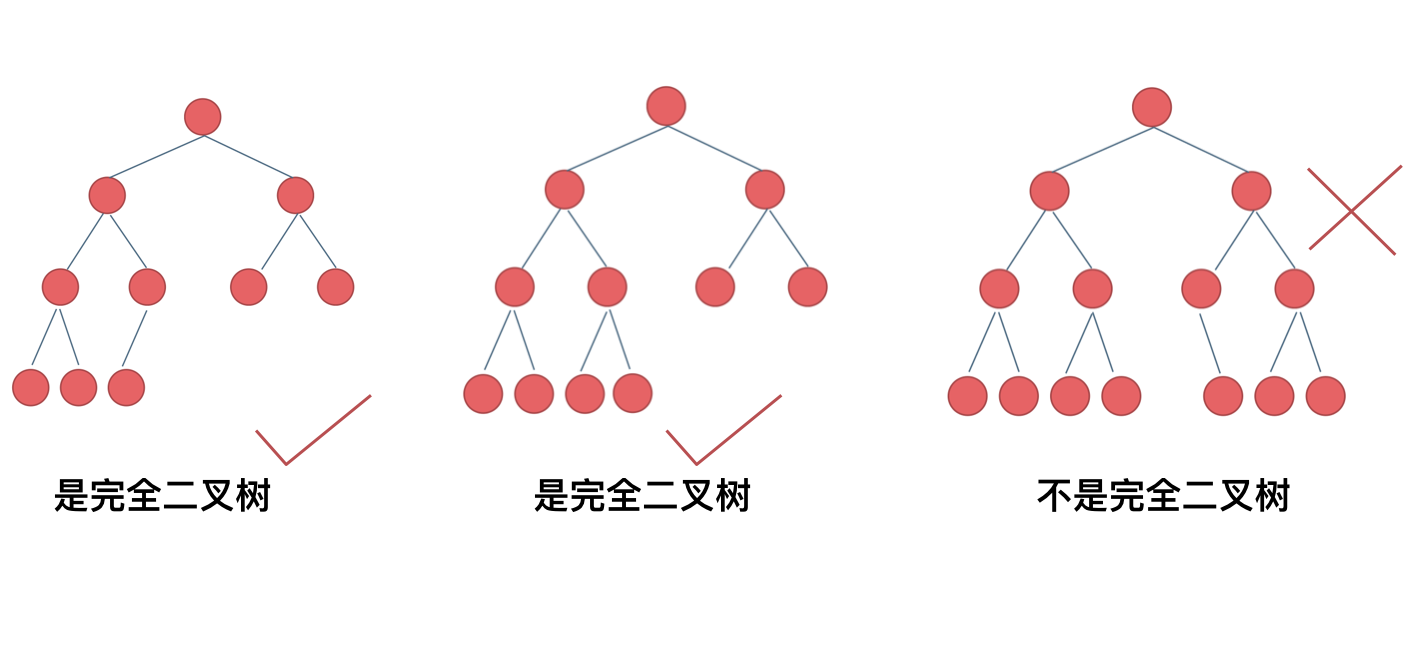
完全二叉树的特点:
- 所有的叶节点都出现在最低的两层上
- 对任一节点,如果其右子树的高度为 k ,则其左子树的高度为 或
满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树
优先队列(堆)就是一棵完全二叉树,并保证了父子节点的顺序关系
# 二叉搜索树
二叉搜索树,也叫作 二叉树查找树 或者 二叉排序树
二叉搜索树的性质:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若右子树不空,则右子树上所有结点的值均大于它的根结点的值
- 左、右子树也分别为二叉排序树
即,在二叉搜索树中,左子树都比其根节点小,右子树都比其根节点大,递归定义
二叉搜索树 的 中序遍历 一定是 从小到大排序 的
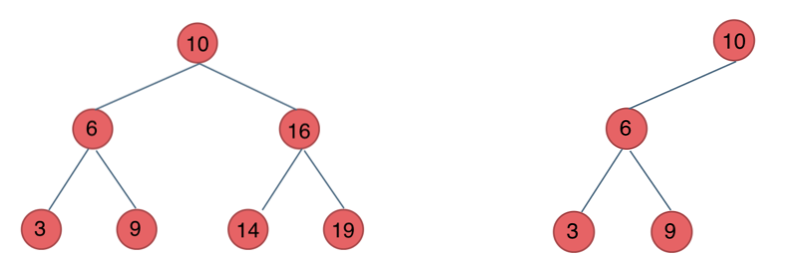
二叉搜索树的搜索性能:
- 最好情况下,二叉搜索树的查找效率比较高,是 ,其访问性能近似于二分法
- 最差情况下,例如插入的元素有序时,生成的二叉搜索树将会是一个链表,搜索的时间复杂度为
# 平衡二叉树
平衡二叉树,又被称为 AVL(Adelson-Velsky and Landis)树,是二叉搜索树的一种实现
平衡二叉树要么是一棵空树,要么保证左右子树的高度差不超过 1,并且左右子树也都必须是一棵平衡二叉树
平衡二叉树的提出就是为了避免二叉搜索树出现极端情况
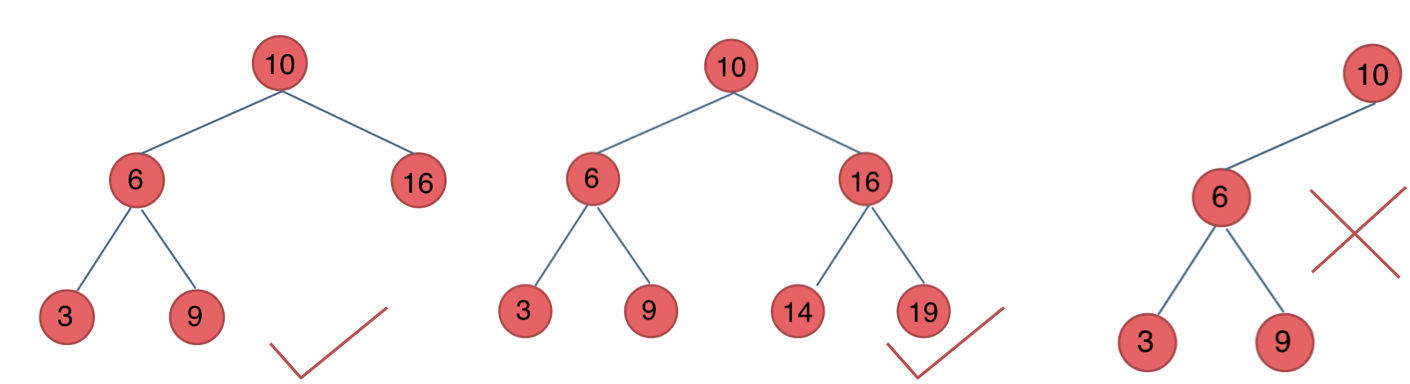
平衡二叉树的性能:平衡二叉树在添加和删除时需要进行复杂的旋转保持整个树的平衡,最终,插入、查找的时间复杂度都是
著名的红黑树就是一种平衡二叉树
C++ 中, map 、 set 、 multimap 、 multiset 的底层实现都是平衡二叉树
# 二叉树的遍历
二叉树有两类遍历方式:深度优先遍历 与 广度优先遍历
# 深度优先遍历
深度优先遍历 可分为:前序遍历、中序遍历、后序遍历
前序遍历 :首先访问 / 处理根节点,然后访问 / 处理左子树,最后访问 / 处理右子树
中序遍历 :先访问 / 处理左子树,然后处理根节点,然后访问 / 处理右子树
后序遍历 :先访问 / 处理左子树,然后访问 / 处理右子树,最后处理树的根节点
严格来说,遍历时一定是先访问根节点,然后根据根节点访问左子节点、右子节点,所谓的 前序、中序、后序遍历 讲的是处理根节点(即,do something with root)的顺序。例如,对于中序遍历,根节点的处理是在处理完左子节点之后才进行的。可参考 前、中、后序遍历的区别
前、中、后序遍历只针对于根节点,而左右子节点永远都是先左后右的顺序
- 前序:根左右
- 中序:左根右
- 后序:左右根
以下图为例

其遍历的结果为:
| 遍历方式 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 前序遍历 | F | B | A | D | C | E | G | I | H |
| 中序遍历 | A | B | C | D | E | F | G | H | I |
| 后序遍历 | A | C | E | D | B | H | I | G | F |
使用:
中序常用来在二叉搜索树中得到递增的有序序列
删除节点的过程将按照后序遍历的顺序进行
后序可用于数学中的后缀表示法,结合栈处理表达式,每遇到一个操作符,就可以从栈中弹出栈顶的两个元素,计算并将结果返回到栈中
深度优先遍历 通常可以用 递归法 和 迭代法 实现(如果采用迭代法,则需要借助 栈 这一数据结构)
具体实现:
- LeetCode 144. 二叉树的前序遍历
- LeetCode 94. 二叉树的中序遍历
- LeetCode 145. 二叉树的后序遍历
# 广度优先遍历
二叉树的广度优先遍历是指 层次遍历
即,逐层地、从左到右访问所有节点
上述例子的层序遍历结果为:
| 遍历方式 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 层序遍历 | F | B | G | A | D | I | C | E | H |
广度优先遍历 一般借助 队列 这一数据结构、采用 迭代法 实现
具体实现:LeetCode 102. 二叉树的层序遍历
# 二叉树的定义
已知二叉树的前序遍历序列和中序遍历序列,可以确定一棵二叉树
- 根据前序遍历序列找出根节点,再根据中序遍历序列区分左右子树
- 分别找出左右子树的前序、中序遍历序列
- 分别对左右子树重复这个过程
例:
前序序列:A B D E F C
中序序列:D B E F A C
根据前序序列确定二叉树的根节点为 A ,在中序序列中找到 A ,此时,中序序列中 A 左边的 D B E F 即为 A 的左子树,A 右边的 C 为 A 的右子树
- 针对 A 的左子树,一共包含 D B E F 四个节点,其对应的前序遍历为 B D E F ,中序遍历为 D B E F 。因此, A 的左子树的根节点为 B ,节点 B 的左子树为 D ,右子树为 E F
- 针对 B 的右子树,一共包含 E F 两个节点,其前序遍历为 E F ,中序遍历为 E F
- 根节点为 E ,右子树为 F
- 针对 B 的右子树,一共包含 E F 两个节点,其前序遍历为 E F ,中序遍历为 E F
- 针对 A 的右子树,前序遍历和中序遍历均为 C,故 C 为叶节点

已知二叉树的中序遍历序列和后序遍历序列,可以确定一棵二叉树
- 根据后序遍历确定根节点,根据中序遍历确定其左右子树
已知二叉树的前序遍历序列和后序遍历序列,无法唯一确定一棵二叉树
- 可以根据前序遍历序列确定根节点,但无法分清其左子树和右子树
# 二叉树的性质
一棵非空二叉树的第 层上最多有 个节点
一棵高度为 的二叉树,最多具有 个节点
一棵非空二叉树,如果叶节点数为 ,度数为 2 的节点数为 ,则有 成立
- 二叉树所有节点的度数均小于或等于 2,所以有
- 除根节点外,每个节点都有唯一的一个树枝(父节点与子节点之间的线段)进入本节点,则二叉树的树枝总数
- 度为 1 的节点发出一个树枝,度为 2 的节点发出两个树枝,所以
- 联立以上三式,得
具有 个节点的完全二叉树的高度 $ k = \lfloor \log_2 {n} \rfloor + 1$
- 高度为 的完全二叉树,其节点总数满足 ,化简得 ,由于 是整数,所以有
完全二叉树的按层编号:对一棵有 个节点的完全二叉树中的节点按层自上而下(从第 1 层到第 层)、每一层层按自左至右依次编号,若设根节点的编号为 ,则对任一编号为 的节点,有:
- 若 ,则节点为二叉树的根节点;若 ,则其父节点的编号为
- 若 ,则编号为 的节点为叶节点,没有子节点;否则,其左子节点编号为
- 若 ,则编号为 的节点无右子节点;否则,其右子节点编号为
# 二叉树的存储
# 顺序存储
# 完全二叉树的顺序存储
按层编号,把节点的层次关系映射到线性关系
并且,根据 完全二叉树的按层编号 性质,可以得知各节点的父节点和子节点
例如:

# 非完全二叉树的顺序存储
将非完全二叉树修补成完全二叉树
- 用特殊标记 (对应于类定义中的
flag)表示虚拟节点
然后按层编号
例如:

非完全二叉树顺序存储的特点:浪费空间(极端情况:只有右子节点的高为 3 的二叉树,其需要 7 个节点的存储空间,但是有效的节点只有 3 个)
一般只用于一些特殊的场合,如静态的并且节点个数已知的完全二叉树或接近完全二叉树的二叉树
# 链接存储
# 二叉链表
指明子节点,类似于单链表
每个节点存储 数据元素、指向左子节点的指针、指向右子节点的指针
例如:

# 三叉链表:
同时指明父节点和子节点,类似于双链表
每个节点存储 数据元素、指向左子节点的指针、指向右子节点的指针、指向父节点的指针

由于在二叉树中很少通过子节点找父节点,因此,我们常使用二叉链表进行存储,二叉链表也被称作二叉树的标准存储方式
# 二叉树节点的定义
使用二叉链表来定义二叉树
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
注意,在 Leetcode 中,数据结构都是定义了的,而在笔试 / 面试时可能需要自行定义数据结构,例如,链表、二叉树等
因此,一定要掌握数据结构的定义
参考:
- 青州智学
- 代码随想录
- 图解算法数据结构
